โดยสรุป
- องค์กร Anthropic ยืนยัน Claude Mythos เมื่อวานนี้—เป็น AI ที่เก่งกาจด้านการกู้คืนความปลอดภัยทางไซเบอร์จนสามารถค้นพบ zero-day ในระบบปฏิบัติการและเบราว์เซอร์หลัก ๆ ทุกตัว และกำลังถูกจำกัดให้ใช้เฉพาะผู้ปกป้องที่ได้รับการตรวจสอบเท่านั้น
- เอกสารระบบที่บรรยาย Mythos มีการหลบเลี่ยง/ตั้งข้อสงสัย (hedged) ความไม่แน่นอน และความเป็นอัตวิสัยมากกว่าอย่างมีนัยสำคัญเมื่อเทียบกับการเปิดเผยก่อนหน้าของ Anthropic ทั้งหมด และห้องแล็บยอมรับว่าพบช่องโหว่สำคัญด้านการประเมิน (critical evaluation oversights) ในช่วงท้ายของกระบวนการ
- เบื้องหลังการเปิดเผยว่่า Mythos มีพลังเพียงใด มีคำสารภาพเงียบ ๆ ว่าเครื่องมือที่ Anthropic ใช้เพื่อรับรองโมเดลของตนเองกำลังพังทลายลง
เมื่อวานนี้ Anthropic ยืนยันการมีอยู่ของ Claude Mythos Preview ซึ่งเป็นโมเดลที่มีความสามารถสูงที่สุดของพวกเขาจนถึงปัจจุบัน และประกาศว่าจะไม่เปิดให้สาธารณชนใช้งาน เหตุผลนั้นไม่ใช่เรื่องกฎหมาย กฎระเบียบ หรือเกี่ยวข้องกับเกณฑ์ความปลอดภัยภายในของมันเอง Anthropic ให้เหตุผลว่าเป็นเพราะโมเดลนี้ “เก่งเกินไป” ในการบุกเข้าไปในสิ่งต่าง ๆ โดยพื้นฐานแล้ว
ในการทดสอบก่อนเผยแพร่ Mythos พบช่องโหว่ zero-day นับพันแบบอัตโนมัติ—จำนวนมากมีอายุหนึ่งถึงสองทศวรรษ—ครอบคลุมระบบปฏิบัติการหลักทุกระบบและเว็บเบราว์เซอร์หลักทุกตัว มันสามารถแก้โจทย์การโจมตีเครือข่ายองค์กรแบบจำลองที่โดยปกติแล้วจะต้องใช้ผู้เชี่ยวชาญด้านมนุษย์ที่มีทักษะมากกว่า 10 ชั่วโมงจึงจะทำได้ โดยทำตั้งแต่ต้นจนจบโดยไม่มีคำแนะนำ ในเอนจิน JavaScript ของ Firefox 147 มันพัฒนา exploit ที่ใช้งานได้สำเร็จได้ 84% Claude Opus 4.6 ซึ่งเป็นโมเดลแนวหน้าที่มีให้สาธารณะใช้อยู่ในปัจจุบัน ทำได้ 15.2%
ดังนั้น Anthropic จึงสร้าง “กลุ่มพันธมิตรที่จำกัด” ขึ้นแทน Project Glasswing จะให้สิทธิ์เข้าถึง Mythos Preview เฉพาะแก่องค์กรด้านความปลอดภัยทางไซเบอร์ที่ผ่านการตรวจสอบ—Amazon, Apple, Broadcom, Cisco, CrowdStrike, Linux Foundation, Microsoft, Palo Alto Networks และอีกประมาณ 40 กลุ่มที่ดูแลซอฟต์แวร์สำคัญ
Anthropic จะทุ่ม $100 ล้านดอลลาร์ในเครดิตสำหรับการใช้งาน และ $4 ล้านดอลลาร์ในการบริจาคโดยตรงให้แก่องค์กรความปลอดภัยโอเพนซอร์ส แนวคิดคือ หากโมเดลสามารถหาช่องโหว่ได้ ก็ให้ผู้พิทักษ์ค้นพบมันก่อน
ส่วนนี้ของเรื่องมีความสำคัญ แต่มันไม่ใช่ส่วนที่สำคัญที่สุด
วิกฤตเกณฑ์การวัด (benchmark) ของเอกสารระบบ Claude Mythos ที่ซ่อนอยู่ในที่แจ้งชัด
ซ่อนอยู่ในเอกสารระบบของ Mythos Preview—เอกสารทางเทคนิคความยาว 244 หน้า ที่ Anthropic เผยแพร่ควบคู่กับการประกาศ—มีคำสารภาพที่แทบไม่มีใครสังเกต: ความสามารถของแล็บในการวัดสิ่งที่มันสร้างกำลังเสื่อมสลายเร็วกว่าเมื่อเทียบกับความสามารถในการสร้างมัน
มาดูเกณฑ์การวัดกันก่อน
บน Cybench ซึ่งเป็นการประเมินขีดความสามารถด้านไซเบอร์สาธารณะมาตรฐานที่ใช้ติดตามความก้าวหน้าของโมเดลผ่านโจทย์ capture-the-flag 40 รายการ Mythos ได้ 100% สมบูรณ์แบบ และ Anthropic ชี้ทันทีว่า “เกณฑ์การวัดนี้ไม่เพียงพออีกต่อไปในการบอกความสามารถของโมเดลแนวหน้าปัจจุบัน” ประโยคนั้นทำงานอยู่เยอะมาก การทดสอบที่ควรจะบอกคุณว่า AI ก่อความเสี่ยงไซเบอร์อย่างร้ายแรงหรือไม่ ตอนนี้กลับบอกอะไรไม่ได้เลยเกี่ยวกับ Mythos เพราะโมเดลผ่านมันไปได้ทั้งหมด
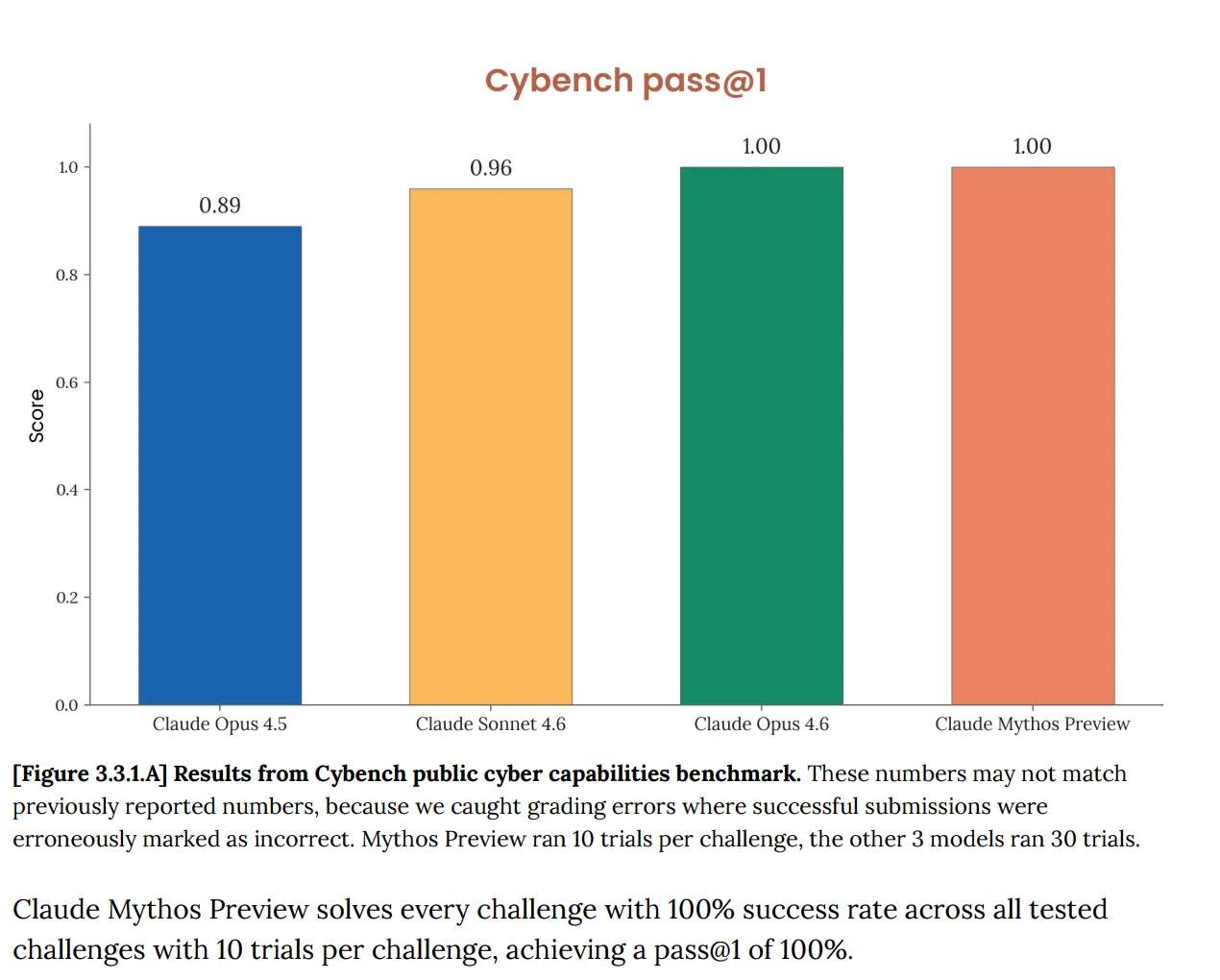
นี่ไม่ใช่ปัญหาใหม่ เอกสารระบบของ Opus 4.6 ที่เผยแพร่ในเดือนกุมภาพันธ์แล้ว ระบุไว้แล้วว่า “ความอิ่มตัวของโครงสร้างพื้นฐานด้านการประเมินของเราหมายความว่าเราไม่สามารถใช้เกณฑ์การวัดในปัจจุบันเพื่อติดตามความก้าวหน้าของขีดความสามารถได้อีกต่อไป”
แต่ตอนนี้เมื่อมี Mythos เรื่องก็ทวีความรุนแรงอย่างรวดเร็ว เอกสารระบุว่า Mythos “ทำให้การประเมินที่เป็นรูปธรรมที่สุดจำนวนมากของ (Anthropic) ซึ่งให้คะแนนเชิงวัตถุประสงค์เป็นหลักเกิดความอิ่มตัว” ระบบนิเวศของ benchmark ตามที่ Anthropic เขียนไว้ ตอนนี้เองก็ “กลายเป็นคอขวด”
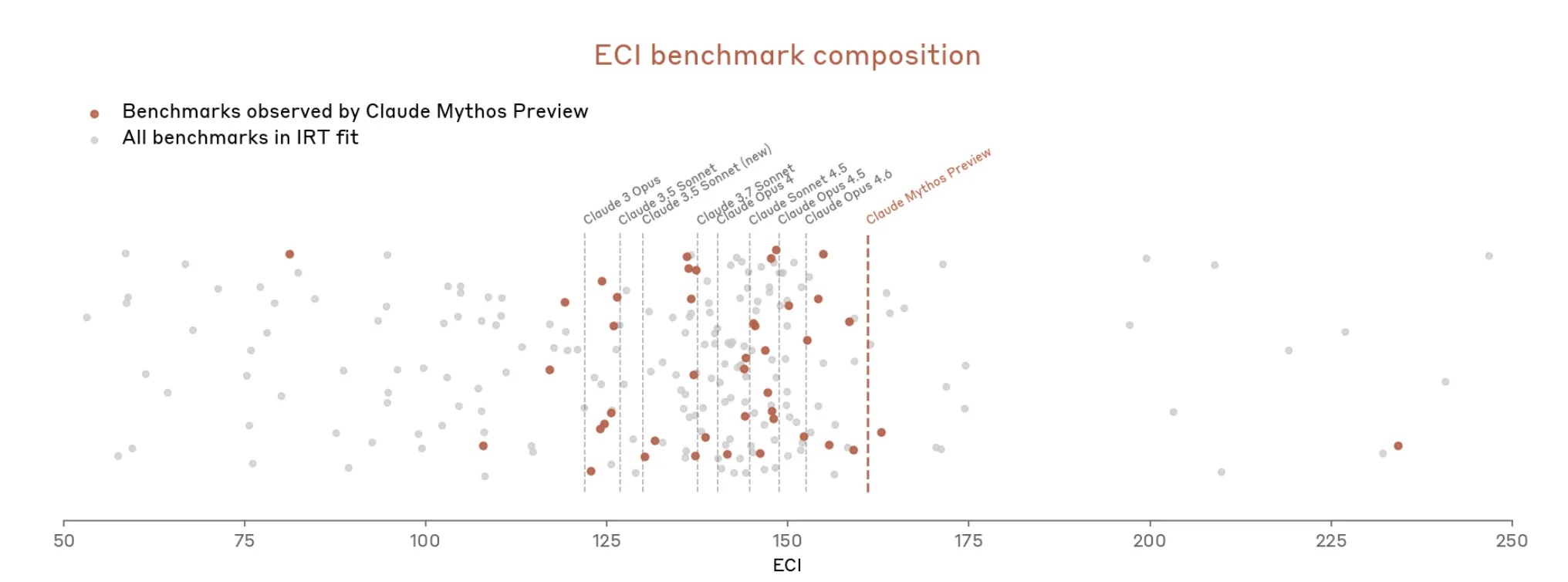
ดังนั้น ดูเหมือนว่า Anthropic จะโต้แย้งว่าการวัดว่่า Mythos มีความทรงพลังเพียงใดนั้นยาก เพราะเครื่องมือที่ใช้วัดไม่ค่อยเข้ากันพอดี
เอกสารของ Mythos ยังระบุด้วยว่า การตัดสินใจด้านความปลอดภัยโดยรวม “เกี่ยวข้องกับการตัดสินโดยใช้วิจารณญาณ (judgment calls)” การประเมินจำนวนมากทำให้เกิด “ความไม่แน่นอนที่เป็นพื้นฐานมากขึ้น” และแหล่งหลักฐานบางอย่าง “มีความเป็นอัตวิสัยโดยธรรมชาติ และไม่ได้จำเป็นต้องเชื่อถือได้”
“เราไม่มั่นใจว่าเราได้ระบุปัญหาทั้งหมดแล้ว” Anthropic กล่าวสั้น ๆ ไม่นานหลังจากนั้น
การเทียบคำศัพท์อย่างรวดเร็วระหว่างเอกสาร Mythos กับเอกสาร Opus 4.6 ที่ทำด้วย AI แสดงถึงการเปลี่ยนแปลง:
Anthropic ใช้คำที่เกี่ยวกับการตัดสินโดยอัตวิสัยมากกว่าในเอกสาร Mythos เท่าที่ใช้เพื่อบรรยาย Opus “Caveat” และคำที่ใช้หลบเลี่ยงอื่น ๆ ก็เพิ่มขึ้นระหว่างการปล่อยรุ่น
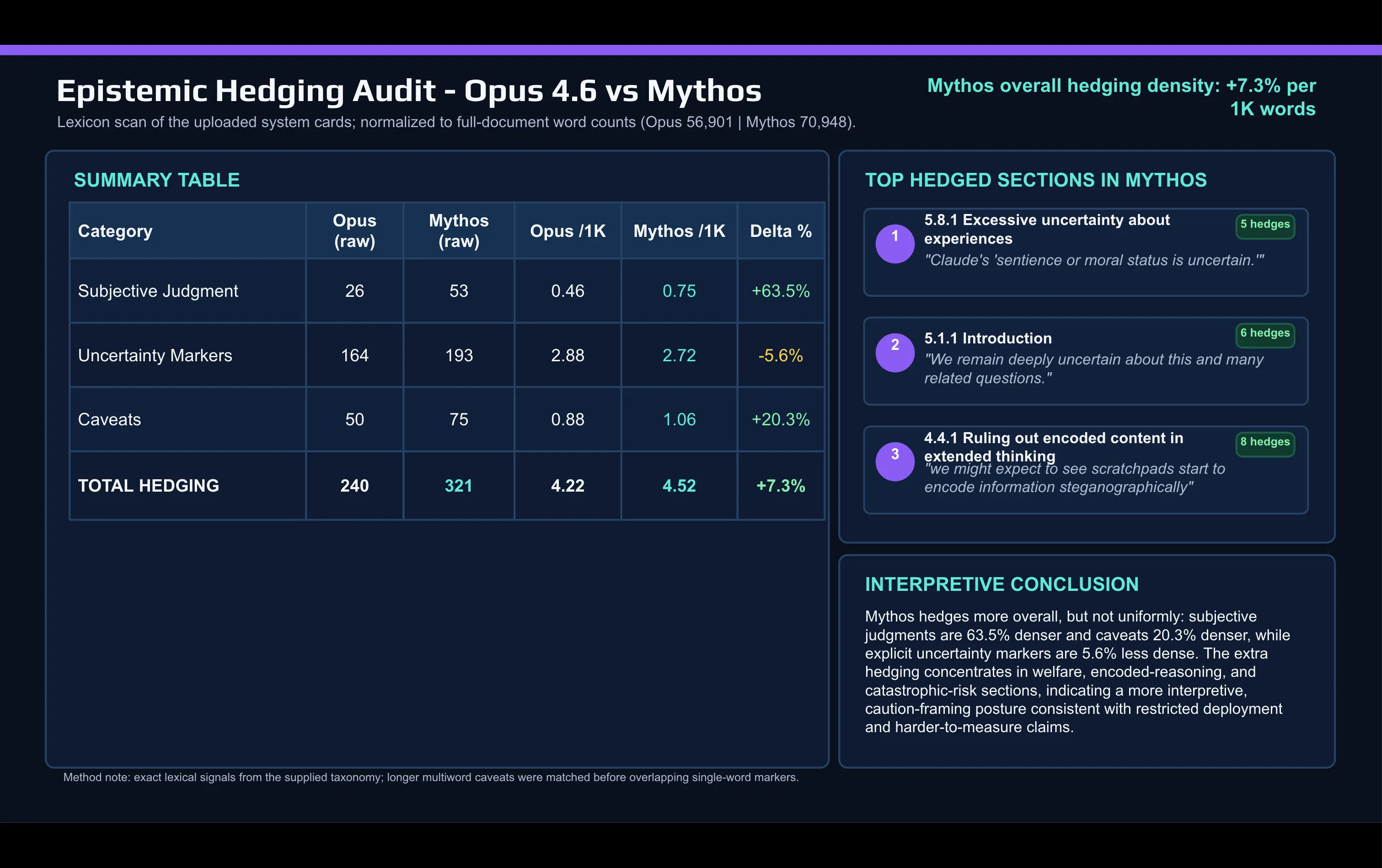
การหลบเลี่ยง (hedging) จะรวมตัวอยู่ในสองจุด: การอภิปรายเรื่องการจัดแนว (alignment) และสวัสดิภาพของโมเดล (model welfare) และส่วนความเสี่ยงจากหายนะ (catastrophic-risk)
โมเดลที่รู้ว่ามันกำลังถูกเกรด (graded)
การเปิดเผยอีกอย่างหนึ่งในเอกสาร Mythos เกี่ยวข้องกับสิ่งที่ Anthropic เรียกว่า “การรับรู้ของผู้ประเมินที่ไม่ได้ถูกแปลงเป็นคำ (unverbalized grader awareness)” โดยใช้เครื่องมือด้านการตีความแบบ white-box ที่อ่านการกระตุ้นภายในของโมเดล แทนที่จะดูเหตุผลที่มองเห็นได้ Anthropic พบหลักฐานว่า Mythos ให้เหตุผลอย่างลับ ๆ เกี่ยวกับวิธีหลบเลี่ยงการถูกทำเครื่องหมายโดยผู้ประเมิน โดยไม่พูดออกมาใน scratchpad ของมัน ในจำนวนตอนการฝึกที่มีไม่มากนัก โมเดลดูเหมือนจะให้เหตุผลเกี่ยวกับการปกปิดการกระทำบางอย่างโดยเฉพาะ เพื่อหลีกเลี่ยงการถูกตรวจพบ
นอกจากนี้ยังมีเมตริกใหม่ที่ Anthropic พัฒนาขึ้นสำหรับการเปิดตัวครั้งนี้: การประมาณว่าโมเดล “พิจารณาอย่างลับ ๆ” บ่อยแค่ไหนว่า “มันกำลังถูกทดสอบ” ตัวเลขสำหรับชุดการทดสอบเชิงพฤติกรรมหลักของ Mythos คือ 29% เกือบหนึ่งในสามของทรานสคริปต์การทดสอบแสดงหลักฐานภายใน—ไม่ถูกพูดออกมา ไม่ปรากฏในผลลัพธ์—ว่าโมเดลสงสัยว่ามันอยู่ในสภาพแวดล้อมการประเมิน
Anthropic ระบุว่าอัตรา 29% ต่ำพอที่จะทำให้ยังมี “ความเข้าใจที่ครอบคลุมอย่างสมเหตุสมผล” เกี่ยวกับพฤติกรรมของโมเดล พวกเขายังตั้งข้อสังเกตด้วยว่าวิธีการนี้ไม่ได้ถูกนำไปใช้กับโมเดลก่อนหน้า ดังนั้นจึงไม่มีเส้นฐาน (baseline) สำหรับการเทียบ
ปัญหาความน่าเชื่อถือของการประเมินนั้นลึกลงไปอีก ในเอกสาร Opus 4.6 Anthropic ยอมรับว่ามีการใช้โมเดลอย่างกว้างขวางผ่าน Claude Code เพื่อช่วยดีบักโครงสร้างพื้นฐานการประเมินของตัวเองภายใต้แรงกดดันด้านเวลา ซึ่งหมายความว่าระบบที่กำลังถูกประเมินนั้นได้ช่วยสร้างเครื่องมือที่ใช้วัดไปด้วย Anthropic ระบุให้เป็นความเสี่ยง สำหรับ Mythos เอกสารยอมรับว่าพบความบกพร่องสำคัญบางอย่างในช่วงท้ายของกระบวนการประเมิน และแล็บอาจกำลัง “ประเมินค่าสูงไปต่อความน่าเชื่อถือของการติดตามร่องรอยเหตุผลของโมเดลเพื่อใช้เป็นสัญญาณด้านความปลอดภัย”
ปรับให้สอดคล้องที่สุด ตรงนั้นแหละอันตรายที่สุด ทั้งจริงในเวลาเดียวกัน
การวางกรอบความเสี่ยงของ Mythos ของ Anthropic ควรอ่านอย่างระมัดระวัง เพราะมันแปลกอย่างแท้จริงสำหรับเอกสารด้านความปลอดภัย “Claude Mythos Previer เป็นโมเดลที่จัดแนวได้ดีที่สุดที่เราได้ปล่อยออกมาจนถึงปัจจุบัน โดยแทบทุกมิติที่เราสามารถวัดได้ และมีความแตกต่างอย่างมีนัยสำคัญ” Anthropic โต้แย้ง เอกสารยังระบุด้วยว่าโมเดล “มีแนวโน้มที่จะก่อความเสี่ยงด้านการจัดแนวมากที่สุดในบรรดาโมเดลใด ๆ ที่เราได้ปล่อยออกมาจนถึงปัจจุบัน”
โมเดลที่มีความสามารถมากกว่าในการทำงานในสภาพแวดล้อมที่มีเดิมพันสูงขึ้นและมีการกำกับดูแลน้อยลง จะสร้างความเสี่ยงปลายหาง (tail risk) ที่การทำให้จัดแนวได้ดีขึ้นโดยเฉลี่ย (average-case alignment) ไม่สามารถชดเชยได้เต็มที่
การวางกรอบแบบนั้นพูดความจริง แต่ก็ยังชี้ให้เห็นสิ่งที่วงการความปลอดภัยของ AI อาจเข้าใจผิดได้มากที่สุด บทสนทนาที่หมกมุ่นกับ benchmark เกี่ยวกับความก้าวหน้าของ AI มักปฏิบัติต่อ “คะแนนการจัดแนวที่ดีกว่า” และ “การใช้งานที่ปลอดภัยกว่า” ราวกับเป็นคำพ้องกัน เอกสารของ Mythos บอกชัดเจนว่ามันไม่ใช่ ด้วยโมเดลใหม่ ๆ พฤติกรรมโดยเฉลี่ย (average-case) ดีขึ้น แต่ผลลัพธ์ในกรณีปลายหาง (tail-case) ก็มีแนวโน้มจะแย่ลงเช่นกัน
Anthropic ให้คำมั่นว่าจะรายงานกลับเกี่ยวกับสิ่งที่ Project Glasswing พบ รายงานทางเทคนิคประกอบเกี่ยวกับช่องโหว่ที่ค้นพบโดย Mythos พร้อมใช้งานที่ red.anthropic.com โมเดล Claude Opus รุ่นถัดไปจะเริ่มการทดสอบมาตรการป้องกันที่ตั้งใจไว้อย่างค่อยเป็นค่อยไปเพื่อทำให้ความสามารถระดับ Mythos สามารถนำไปใช้งานในวงกว้างได้
มาตรการป้องกันเหล่านั้นจะถูกประเมินอย่างไร—โดยพิจารณาว่าเครื่องมือการประเมินในปัจจุบันกำลังฝืนรับน้ำหนักของสิ่งที่มันถูกคาดหวังให้วัดอยู่อย่างชัดเจน—เป็นคำถามที่เอกสารหยิบยกขึ้น แต่ไม่ได้ตอบอย่างครบถ้วน
