人工智能系統的演變:從 Web2 到 Web3
在之前的文章中,我們回顧了應用設計的歷史。而在本篇“Agentic AI”系列的第二篇文章第一部分,我們將聚焦 Web2 時代的 AI 生態,分析其發展趨勢、代表性平臺和關鍵技術。在第二部分中,我們將進一步探討區塊鏈和去信任化驗證技術如何推動 AI 代理系統向真正的自主智能系統演進。
1. Web2 時代的 AI 代理生態
中心化 AI 代理的現狀

當前的 AI 生態仍然由大型科技公司主導,它們控制著中心化的平臺和服務。OpenAI、Anthropic、Google 和 Microsoft 等公司不僅提供先進的大型語言模型(LLMs),還負責維持關鍵的雲計算基礎設施和 API 服務,支撐著大多數 AI 代理的運行。
AI 代理基礎設施
隨著 AI 技術的進步,開發 AI 代理的方式也發生了巨大變化。開發者無需編寫繁瑣的代碼,而是可以直接使用自然語言定義 AI 代理的行為和目標,使其更具靈活性和智能性。

圖 2:AI 代理基礎設施示意圖
AI 代理的發展主要得益於以下幾個關鍵領域的突破:
- 高級大型語言模型(LLMs):
LLMs 徹底改變了 AI 代理對自然語言的理解和生成方式,取代了傳統的基於規則的系統,具備更先進的理解能力。它們通過“鏈式思維”推理實現複雜的推理和規劃能力。
目前,大多數 AI 應用都建立在中心化的 LLM 模型之上,例如 OpenAI 的 GPT-4、Anthropic 的 Claude,以及 Google 的 Gemini。
開源 AI 模型包括 DeepSeek、Meta 的 LLaMa、Google 的 PaLM 2 和 LaMDA、Mistral AI的 Mistral 7B、xAI 的 Grok 和 Grok-1、LM Studio 的 Vicuna-13B 以及阿布扎比技術創新研究院(TII)開發的 Falcon 模型。
- 代理框架:
許多新興框架和工具正在幫助企業更輕鬆地構建多代理 AI 應用。這些框架支持各種 LLM,並提供預構建的功能,如記憶管理、自定義工具和外部數據集成,從而大大減少開發難度,加速 AI 代理的創新和落地。
主要的代理框架包括 Phidata、OpenAI Swarm、CrewAI、LangChain LangGraph,、LlamaIndex、、開源的 Microsoft Autogen, Vertex AI 和 LangFlow,它們使開發 AI 助手的代碼需求降至最低。
- 自主 AI 平臺:
自主 AI 平臺旨在協調多個 AI 代理,使其在分佈式環境下自主解決複雜問題。這些系統能夠動態適應和協作,為 AI 代理的擴展提供穩健的解決方案。它們的目標是使 AI 代理技術更易於企業應用,並能直接集成到現有系統中。
主要的自主 AI 平臺包括 Microsoft Autogen、Langchain LangGraph、Microsoft Semantic Kernel 和 CrewAI。
- 檢索增強生成(RAG):
RAG 允許 LLM 在回答查詢之前訪問外部數據庫或文檔,從而提高準確性並減少幻覺現象。RAG 的發展使 AI 代理能夠適應並從新信息源中學習,無需頻繁重新訓練模型。
主要的 RAG 工具包括 K2View、Haystack、 LangChain,、LlamaIndex,、RAGatouille,以及開源的 EmbedChain 和InfiniFlow。
- 記憶系統:傳統 AI 代理在處理長期任務時存在侷限性,而記憶系統可提供短期記憶用於中間任務,或長期記憶用於存儲和檢索更長期的信息。
長期記憶包括:- 情景記憶:記錄特定的經驗,以便在當前查詢中學習和解決問題。
- 語義記憶:存儲關於 AI 代理環境的通用和高層信息。
- 程序記憶:記錄決策過程和解決數學問題的步驟。
- 主要的記憶服務提供商包括 Letta、開源 MemGPT、Zep 和Mem0。
- 零代碼 AI 平臺:
這類平臺允許用戶通過拖放工具、可視化界面或問答嚮導來構建 AI 模型。用戶可以直接將 AI 代理部署到應用程序中,實現自動化流程。零代碼平臺降低了 AI 代理的開發門檻,使 AI 應用更易於訪問,同時加快開發週期,促進創新。
主要的零代碼平臺包括 BuildFire AI、 Google Teachable Machine 和 Amazon SageMaker。
此外,還有一些專門用於 AI 代理的零代碼平臺,例如 Obviously AI(用於商業預測)、Lobe AI(用於圖像分類)和 Nanonets(用於文檔處理)。

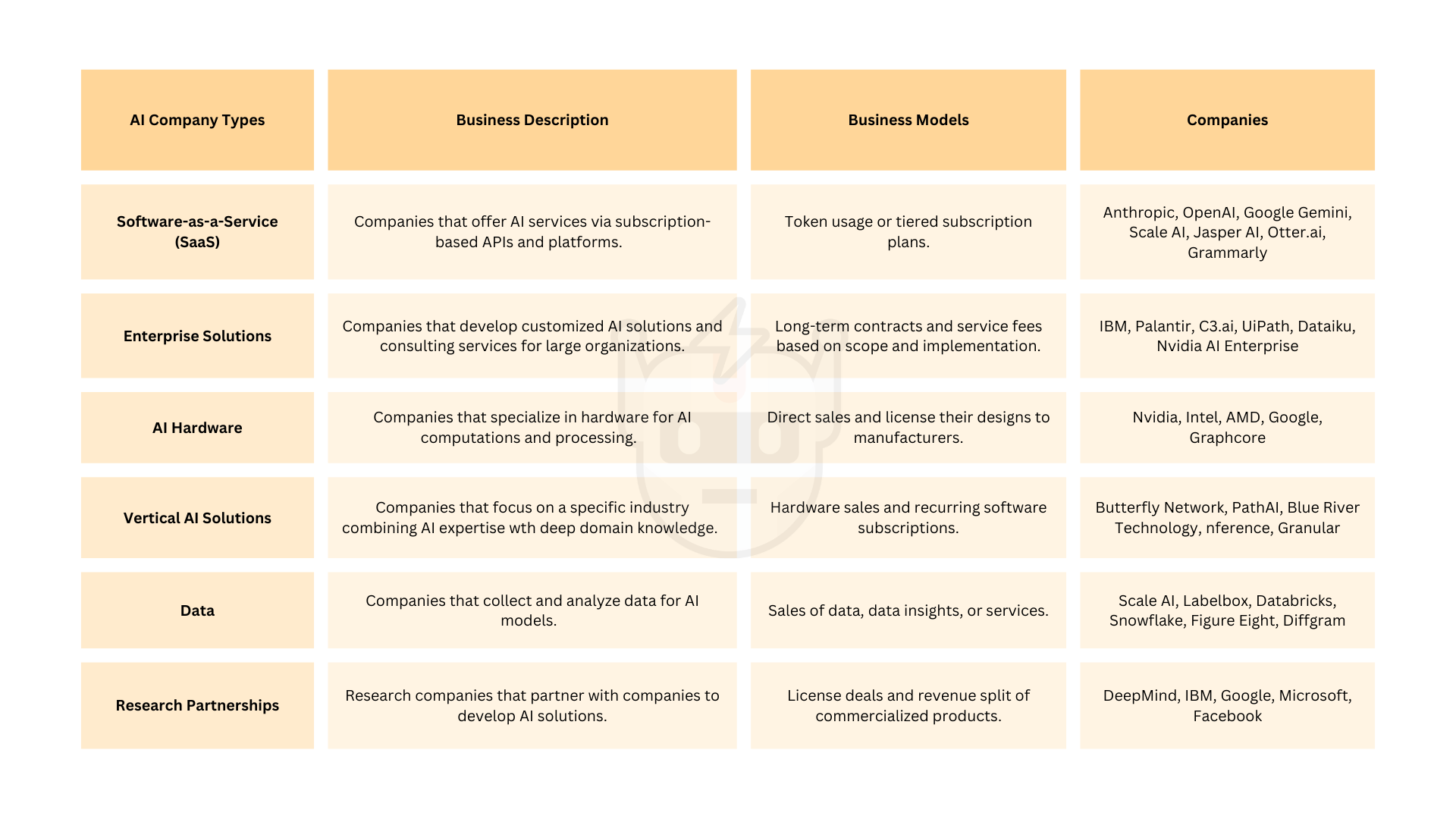
圖 3:AI 業務模型示意圖
{kind=link}
業務模型
傳統的 Web2 AI 公司主要採用分層訂閱和諮詢服務作為其商業模式。
新興的 AI 代理商業模式包括:
- 訂閱 / 按使用量收費模式: 按代理運行次數或計算資源消耗計費,類似於 LLM 服務。
- 市場模式: 代理平臺從平臺上的交易中抽取佣金,類似於應用商店模式。
- 企業授權: 提供定製化的 AI 代理解決方案,並收取實施與支持費用。
- API 訪問: 代理平臺提供 API,允許開發人員集成 AI 代理,並根據 API 調用次數或使用量收費。
- 開源+高級功能: 開源項目提供基礎功能免費使用,但對高級功能、託管服務或企業支持收費。
- 工具集成: 代理平臺可能向 API 提供商或工具服務商收取使用費用或抽成。
2.中心化AI的侷限性
儘管當前的 Web2 AI 系統推動了技術和效率的提升,但它們仍然面臨諸多挑戰:
- 中心化控制:AI 模型和訓練數據集中掌握在少數大型科技公司手中,這帶來了訪問權限受限、模型訓練受控以及垂直整合強制實施的風險。
- 數據隱私和所有權:用戶無法控制自己的數據如何被使用,也無法獲得因其數據被用於 AI 訓練而應得的補償。此外,數據的集中存儲構成了單點故障風險,可能成為數據洩露的目標。
- 透明度問題:中心化 AI 模型的“黑箱”特性使用戶無法理解其決策過程,也無法驗證訓練數據的來源。基於這些模型構建的應用程序無法解釋可能存在的偏見,用戶對其數據的使用方式幾乎沒有任何控制權。
- 合規挑戰:全球範圍內關於 AI 使用和數據隱私的監管環境複雜多變,給合規帶來了不確定性。基於中心化 AI 模型構建的 AI 代理和應用可能受到模型所有者所在國家的法規約束。
- 對抗性攻擊:AI 模型容易受到對抗性攻擊,即通過修改輸入數據來欺騙模型,使其生成錯誤的輸出。因此,需要驗證輸入和輸出的有效性,並加強 AI 代理的安全性和監控措施。
- 輸出可靠性:AI 模型的輸出需要經過技術驗證,並採用透明、可審計的流程來確保其可信度。隨著 AI 代理規模的擴大,AI 生成結果的正確性變得尤為重要。
- 深度偽造:由 AI 生成或修改的圖像、語音和視頻(即“深度偽造”)帶來了嚴重挑戰,它們可能被用於傳播虛假信息、製造安全威脅,並削弱公眾信任。
3.去中心化 AI 解決方案
Web2 AI 的主要限制——中心化、數據所有權和透明度問題——正在通過區塊鏈和代幣化機制得到解決。Web3 提供了以下解決方案:
- 去中心化計算網絡:AI 模型可以使用分佈式計算網絡進行訓練和推理,而不是依賴於中心化的雲服務提供商。
- 模塊化基礎設施:小型團隊可以利用去中心化計算網絡和數據 DAO(去中心化自治組織)來訓練新的特定 AI 模型。開發者可以使用模塊化工具和可組合的基本組件來增強 AI 代理的能力。
- 透明且可驗證的系統:Web3 通過區塊鏈提供了一種可驗證的方式來追蹤 AI 模型的開發和使用情況。模型的輸入和輸出可以通過零知識證明(ZKPs)和可信執行環境(TEEs)進行驗證,並永久記錄在區塊鏈上。
- 數據所有權與自主權:數據可以通過數據市場或數據 DAO 進行變現,這些 DAO 將數據視為集體資產,並可以將數據使用帶來的利潤重新分配給 DAO 貢獻者。
- 網絡引導:代幣激勵機制可以幫助去中心化計算網絡、數據 DAO 和 AI 代理市場的早期貢獻者獲得獎勵,從而促進網絡的發展。代幣經濟激勵可以解決初期的協調難題,推動網絡的採用和增長。
4. Web3 AI 代理生態
Web2 和 Web3 AI 代理的技術架構在核心組件上存在共性,例如模型和資源協調、工具和其他服務、以及用於上下文保留的記憶系統。然而,Web3 通過引入區塊鏈技術,實現了以下去中心化特性:
- 計算資源的去中心化
- 通過代幣激勵促進數據共享和用戶數據所有權
- 通過智能合約實現無需信任的執行
- 通過代幣機制協調去中心化網絡的啟動

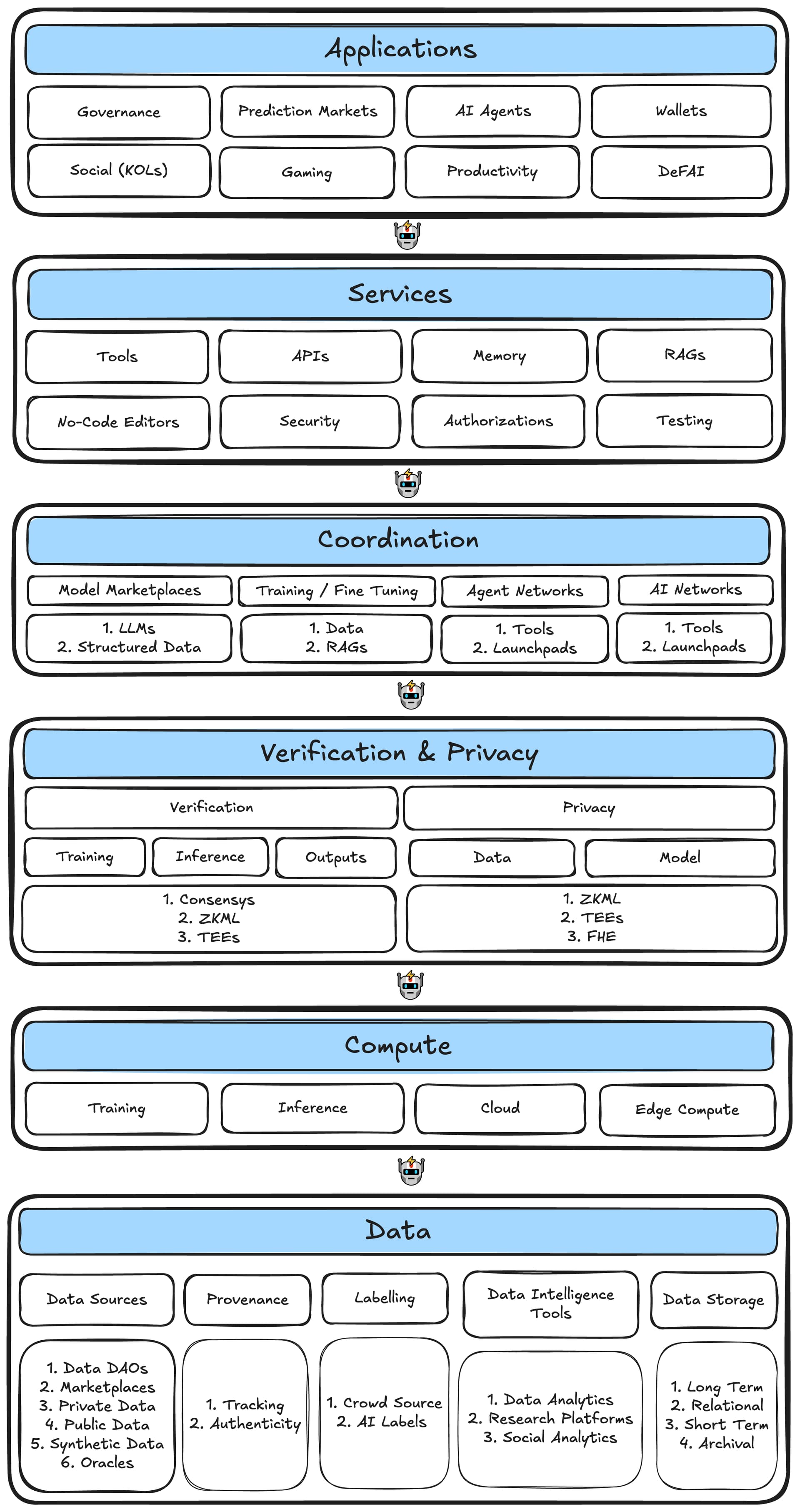
圖 4:Web3_AI代理技術架構
{kind=link}
數據層
數據層是 Web3 AI 代理技術架構的基礎,涵蓋數據的各個方面,包括數據來源、溯源追蹤和真實性驗證、標註系統、數據分析和研究工具,以及不同的數據存儲解決方案。
1.數據來源:數據來源指的是 Web3 AI 生態系統中數據的不同來源。
- 數據 DAO:數據 DAO 是由社區管理的數據組織,旨在促進數據共享和變現。例如Vana 和 Masa AI。
- 數據市場:由 Ocean Protocol 和Sahara AI 等平臺提供的去中心化數據交易市場,使數據交換更加自由和透明。
- 私人數據:個人社交、金融和醫療數據可以在鏈上匿名化,使用戶能夠自主變現。例如,Kaito AI 通過 X(推特) 索引社交數據,並通過 API 生成情緒數據。
- 公共數據:Web2 爬取服務(如 Grass)收集公開數據,並將其預處理成結構化數據,以用於 AI 訓練。
- 合成數據:由於可用的公共數據有限,基於真實數據生成的合成數據成為 AI 訓練的替代方案。例如,Modeʻs Synth Subset 提供專門為 AI 訓練和測試而創建的合成價格數據集。
- 預言機(Oracles):預言機聚合鏈下數據,並通過智能合約連接區塊鏈。AI 相關的預言機包括 Ora Protocol、Chainlink和 Masa AI。
2.數據溯源:數據溯源對於確保數據完整性、減少偏見、提高可追溯性至關重要。數據溯源技術能夠記錄數據的起源,並追蹤數據的變更歷史,以確保 AI 訓練數據的可靠性。Web3 解決方案包括:
基於區塊鏈的元數據: 通過區塊鏈記錄數據的來源及其修改歷史(代表項目 Ocean Protocol 和 Filecoin’s Project Origin)。
去中心化知識圖譜: 追蹤數據流向並提供可驗證的數據來源(如 OriginTrail)。
零知識證明: 生成數據溯源和審計的加密證明,以提高數據的可信性(如 Fact Fortress 和 Reclaim Protocol)。
3.數據標註: 傳統上需要人工對數據進行分類和標記,以便用於監督學習模型的訓練。Web3 通過代幣激勵機制,鼓勵眾包工作者參與數據預處理。
在 Web2 領域,Scale AI 的年收入達 10 億美元,客戶包括 OpenAI、Anthropic 和 Cohere。而在 Web3 領域,Human Protocol 和 Ocean Protocol 採用眾包模式進行數據標註,並通過代幣獎勵貢獻者,Alaya AI 和 Fetch.ai 則採用 AI 代理執行數據標註任務。
4.數據智能工具:數據智能工具是用於分析和提取數據洞察的軟件解決方案,它們能夠提高數據質量,確保合規性和安全性,並通過優化數據質量來提升 AI 模型的表現。區塊鏈分析公司包括 Arkham、 Nansen 和 Dune,而 Messari提供鏈下研究服務,Kaito 通過 API 提供社交媒體情緒分析,使 AI 模型能夠利用更豐富的數據源進行訓練。
5.數據存儲:採用代幣激勵模式,實現去中心化和分佈式存儲,使數據能夠在獨立的節點網絡中存儲和共享。數據通常經過加密,並分佈在多個節點上,以確保冗餘存儲和隱私安全。
Filecoin 是最早的去中心化存儲項目之一,用戶可以提供閒置硬盤空間存儲加密數據,並獲得代幣獎勵。 IPFS (星際文件系統)通過點對點網絡存儲和共享數據,利用唯一的加密哈希確保數據的完整性。 Arweave 提供永久數據存儲方案,並通過區塊獎勵補貼存儲成本,而 Storj 提供兼容 S3 API 的存儲解決方案,使現有企業應用能夠輕鬆從雲存儲遷移至去中心化存儲系統。
計算層
計算層提供運行 AI 操作所需的處理基礎設施。計算資源可分為不同類別:用於模型開發的訓練基礎設施、用於模型執行和 AI 代理運行的推理系統,以及本地去中心化計算的邊緣計算。去中心化計算資源減少了對中心化雲網絡的依賴,提高了安全性,降低了單點故障的風險,同時允許較小的 AI 公司利用多餘的計算資源。
1.訓練:AI 模型訓練通常計算密集且成本高昂,而去中心化的訓練計算資源能夠使 AI 開發更加民主化,同時提升隱私和安全性,因為敏感數據可以在本地處理,而無需受制於中心化平臺。
- Bittensor 和Golem Network 提供去中心化的 AI 訓練資源市場。
- Akash Network 和Phala 提供帶有可信執行環境(TEEs)的去中心化計算資源。
- Render Network 重新利用其圖形 GPU 網絡,為 AI 計算任務提供計算資源。
2.推理:推理計算指的是模型生成新輸出或 AI 應用及 AI 代理運行所需的計算資源。實時處理大量數據的應用,或需要多次操作的 AI 代理,通常需要更強大的推理計算能力。
- Hyperbolic、 Dfinity 和 Hyperspace 專門提供推理計算服務。
- Inference Labs 的 Omron 是 Bittensor 上的推理與計算驗證市場。
- Bittensor、Golem Network、Akash Network、Phala 和 Render Network 提供訓練與推理計算資源。
3.邊緣計算:邊緣計算指的是在智能手機、物聯網(IoT)設備或本地服務器等遠程設備上進行本地數據處理。由於數據和模型運行在同一設備上,邊緣計算可實現實時數據處理並減少延遲。
- Gradient Network 是 Solana 上的邊緣計算網絡。
- Edge Network、 Theta Network 和 AIOZ 提供全球邊緣計算服務。
驗證/隱私層
驗證與隱私層負責確保系統的完整性和數據安全。共識機制、零知識證明(ZKPs)和可信執行環境(TEEs) 用於驗證模型訓練、推理計算和輸出結果。完全同態加密(FHE)和 TEEs 用於保護數據隱私。
1.可驗證計算:可驗證計算包括模型訓練和推理計算,確保 AI 計算過程可被外部審計和驗證。
- Phala 和 Atoma Network 結合 TEEs 提供可驗證計算。
- Inferium 採用 ZKPs(零知識證明) 和 TEEs 結合的方式,實現可驗證推理計算。
2.輸出證明:輸出證明用於驗證 AI 模型的輸出結果是否真實,確保結果未經篡改,同時不洩露模型參數。輸出證明還提供數據溯源,對於 AI 代理的可信決策至關重要。
- zkML 和 Aztec Network 採用 ZKP 系統,確保計算輸出的完整性。
- Marlin 的 Oyster 通過 TEEs 提供可驗證的 AI 推理計算。
3.數據與模型隱私:完全同態加密(FHE) 和其他密碼學技術使 AI 模型能夠在加密數據上進行計算,而不會暴露敏感信息。在處理個人數據或隱私數據時,數據隱私保護至關重要,可用於保護匿名性。可驗證計算:可驗證計算包括模型訓練和推理計算,確保 AI 計算過程可被外部審計和驗證。
- Oasis Protocol 通過 TEEs 和數據加密 提供機密計算。
- Partisia Blockchain 採用多方計算(MPC),確保 AI 計算過程中的數據隱私。
協調層
協調層促進 Web3 AI 生態系統中不同組件之間的交互,包括模型市場用於 AI 資源分發、訓練和微調基礎設施 以及 代理網絡以實現 AI 代理之間的溝通和協作。
- 模型網絡:模型網絡用於共享 AI 模型開發的資源。
- 大型語言模型(LLMs):訓練 LLM 需要大量計算和數據資源,LLM 網絡允許開發者部署專門化模型。
Bittensor、 Sentient 和 Akash Network 為用戶提供計算資源和市場,以支持 LLM 的開發。
- 結構化數據:結構化數據網絡依賴於定製和經過篩選的數據集。
Pond AI 採用圖模型,創建能夠利用區塊鏈數據的 AI 應用和代理。 - 市場:市場用於變現 AI 模型、代理和數據集。
Ocean Protocol 提供一個市場,允許用戶交易數據、數據預處理服務、AI 模型和模型輸出。
Fetch AI 作為 AI 代理市場,支持 AI 代理的創建和交易。
- 訓練與微調:訓練網絡專注於分發和管理 AI 訓練數據集,而微調網絡專注於通過 RAG和 API 進行模型優化。
Bittensor、Akash Network 和 Golem Network 提供訓練和微調網絡。 - 代理網絡:代理網絡提供兩大核心功能:1)工具: 連接不同協議、提供標準化用戶界面,並與外部服務進行通信。2)代理啟動平臺: 便捷的 AI 代理部署與管理工具。
Theoriq 利用代理群體 提供 DeFi 交易解決方案。
Virtuals 是 Base 上的領先 AI 代理啟動平臺。
Eliza OS 是首個開源 LLM 模型網絡。
Alpaca Network 和 Olas Network 是社區驅動的 AI 代理平臺。
服務層
服務層為 AI 應用和代理提供必要的中間件和工具,確保其高效運行。該層涵蓋開發工具、外部數據 API、記憶系統、檢索增強生成(RAG) 以優化知識訪問,以及測試基礎設施 以確保 AI 代理的可靠性。
- 工具:AI 代理所需的各類工具,提供不同功能支持:
- 支付:集成去中心化支付系統,使 AI 代理能夠自主執行金融交易,實現 Web3 生態中的自動化經濟交互。
Coinbase 的 AgentKit 允許 AI 代理執行支付和代幣轉賬。LangChain 和 Payman 提供支付請求和發送選項。
- 代理啟動平臺:幫助 AI 代理的部署和擴展,提供代幣啟動、模型選擇、API 訪問和工具支持。
Virtuals Protocol 是領先的 AI 代理啟動平臺,支持創建、部署和變現 AI 代理。Top Hat 和 Griffain 是 Solana 生態中的 AI 代理啟動平臺。
- 授權:通過權限管理機制,確保 AI 代理在設定範圍內安全運行。
Biconomy 提供 Session Keys ,允許 AI 代理僅與白名單智能合約 交互。
- 安全性:保護 AI 代理免受攻擊,確保數據完整性和隱私。
GoPlus Security 提供插件,允許 ElizaOS AI 代理 使用 鏈上安全功能,防範詐騙、釣魚和可疑交易。 - 應用程序編程接口 (API):API 使 AI 代理能夠無縫集成外部數據和服務,增強其功能和決策能力。數據訪問 API 為 AI 代理提供實時數據,幫助其做出更準確的決策,而服務 API 使 AI 代理能夠與外部應用程序交互,擴展其功能範圍。
Datai Network 通過結構化數據 API 為 AI 代理提供區塊鏈數據。
SubQuery Network 提供去中心化數據索引器和RPC 端點,支持 AI 代理和應用的運行。
- 檢索增強生成(RAG):RAG 結合大型語言模型(LLMs)與外部數據檢索,提高 AI 代理的知識獲取能力。
- 動態信息檢索:AI 代理可以從外部數據庫或互聯網檢索最新數據,以確保回答的準確性和實時性。
- 知識整合:代理可以將外部數據整合進生成過程,生成更具上下文相關性的回答。
- Atoma Network 提供安全數據管理和公共數據 API,用於定製化 RAG 解決方案。
ElizaOS 和 KIP Protocol 提供 AI 代理插件,連接外部數據源,如 X(推特) 和Farcaster。
- 記憶系統:AI 代理需要記憶系統來保留上下文,並從交互中學習。
短期記憶:代理可以保留交互歷史,以提供更連貫、上下文相關的回答。
長期記憶:代理可以存儲和分析過往交互,提高 AI 代理的個性化能力和長期適應性。
ElizaOS 在其 AI 代理網絡中提供記憶管理功能。
Mem0AI 和 Unibase AI 正在構建 AI 應用和代理的記憶層,增強 AI 代理的長期學習能力。
- 測試基礎設施:AI 代理需要穩定的測試環境來確保其功能的可靠性和穩健性。AI 代理可在受控的模擬環境中運行,以評估其在不同場景下的表現。
Alchemy 的 AI 助手 ChatWeb3 能夠執行復雜查詢和測試,評估 AI 代理的功能實現是否正確。
應用層
應用層是 AI 技術棧的最上層,代表著最終用戶可以直接使用的 AI 解決方案。這些應用涵蓋錢包管理、安全性、生產力提升、遊戲、預測市場、治理系統和 DeFAI(去中心化金融 AI)工具等多個場景。
- 錢包:AI 代理增強 Web3 錢包的功能,解析用戶意圖並自動化複雜交易,從而提升用戶體驗。
Armor Wallet 和 FoxWallet 利用 AI 代理在 DeFi 平臺和區塊鏈上執行用戶意圖,用戶可以通過類似聊天的界面輸入交易需求。Coinbase 開發者平臺 Coinbase 開發者平臺提供 AI 代理管理的 MPC(多方計算)錢包,使其能夠自主轉移代幣。 - 安全:AI 代理可以監測區塊鏈活動,識別欺詐行為和可疑智能合約交易。
ChainAware.ai 的欺詐檢測代理提供實時錢包安全監測和合規檢查,支持多條區塊鏈。代理層的 錢包檢查器 負責掃描錢包漏洞並提供安全優化建議。 - 生產力:AI 代理能夠自動化任務、管理日程安排,並提供智能化推薦,提高用戶效率。
World3 提供無代碼 AI 代理開發平臺,用戶可以設計用於社交媒體管理、Web3 代幣發佈和研究輔助的模塊化 AI 代理。
- 遊戲:AI 代理可控制 NPC(非玩家角色),並根據玩家的動作進行實時調整,提升遊戲體驗。此外,它們還能生成遊戲內容,並幫助新玩家熟悉遊戲。
AI競技場 結合人類玩家的操作數據與模仿學習訓練 AI 遊戲代理。Nim Network 是一個 AI 遊戲公鏈,提供 代理身份(Agent IDs) 和 零知識證明(ZKP),用於跨鏈驗證 AI 代理。Game3s.GG 設計能夠自主探索、指導玩家並與人類玩家並肩作戰的 AI 代理。 - 預測市場:AI 代理分析數據,提供洞察,幫助用戶在預測平臺上做出更明智的決策。
GOAT 預測器 是 Ton Network 上的AI代理,為用戶提供數據驅動的市場預測。 SynStation是 Soneium 生態中的社區驅動預測市場,利用 AI 代理輔助用戶決策。 - 治理:AI 代理在去中心化自治組織(DAO)治理中發揮重要作用,自動評估提案、進行社區意願調查、確保防女巫攻擊(Sybil-Free Voting),並執行治理政策。
SyncAI Network 運行 AI 代理,作為Cardano 生態的去中心化治理代表。Olas 提供治理AI代理,負責起草提案、投票並管理 DAO 財庫。ElizaOS 的 AI 代理能夠分析 DAO 論壇和 Discord 數據,提供治理決策建議。 - DeFAI 代理:AI 代理可用於執行代幣交換、識別收益策略、執行交易策略,並管理跨鏈資產再平衡。此外,風險管理代理 可以監控鏈上活動,檢測可疑行為,並在必要時撤回流動性。
Theoriq 的 AI 代理協議 通過AI 代理群體管理 DeFi 交易、優化流動性池並自動化收益策略。Noya 是一個 DeFi 平臺,利用 AI 代理進行風險監控和投資組合管理。
總的來說,這些 AI 應用共同構建了一個安全、透明、去中心化的 AI 生態,專為 Web3 需求設計。
結論
從 Web2 到 Web3 AI 系統的演變標誌著人工智能開發與部署方式的根本性變革。儘管 Web2 時代的中心化 AI 基礎設施 推動了 AI 領域的巨大創新,但它也面臨數據隱私、透明度和中心化控制 等重大挑戰。Web3 AI 技術棧展示了去中心化系統 如何通過數據 DAO、去中心化計算網絡和無需信任的驗證機制 解決這些問題。此外,代幣激勵機制 創造了新的協調機制,有助於推動和維持 這些去中心化網絡的長期發展。
展望未來,AI 代理的崛起代表著這一演變的下一個前沿。在接下來的文章中,我們將探討 AI 代理——從簡單的任務型機器人到複雜的自主系統——如何變得越來越智能和強大。這些 AI 代理與 Web3 基礎設施的結合,再加上對技術架構、經濟激勵和治理結構 的深入思考,有可能創造出比 Web2 時代更加公平、透明和高效 的系統。對於 Web3 和 AI 交叉領域的從業者來說,理解 AI 代理的工作原理、不同的複雜性層級,以及AI 代理與真正自主 AI(Agentic AI) 之間的區別,將是至關重要的。
聲明:
- 本文轉載自 [Flashbots],所有版權歸原作者 [tesa] 所有。如果對本次轉載有任何異議,請聯繫 Gate Learn 團隊,他們將及時處理。
- 免責聲明:本文所表達的觀點和意見僅代表作者個人觀點,不構成任何投資建議。
- Gate Learn 團隊負責本文章的翻譯,未經授權,禁止複製、傳播或剽竊翻譯內容。
分享


相關文章

Arweave:用AO電腦捕捉市場機會

即將到來的AO代幣:可能是鏈上AI代理的終極解決方案

深度分析:AI和Web3能創造什麼樣的火花?

思維網路:全面同態加密和重質押,讓AI專案安全觸手可及

關於GT-協議你需要了解的一切
