Mergulhe mais fundo na leitura cross-L2 para carteiras e outros casos de utilização
Agradecimentos especiais a Yoav Weiss, Dan Finlay, Martin Koppelmann e às equipas Arbitrum, Optimism, Polygon, Scroll e SoulWallet pelo feedback e revisão.
Neste post sobre as Três Transições, delineei algumas razões fundamentais pelas quais é importante começar a pensar explicitamente no suporte L1 + cross-L2, na segurança das carteiras e na privacidade como características básicas necessárias do ecossistema, em vez de criar cada uma destas coisas como complementos que podem ser concebidos separadamente por carteiras individuais.
Esta publicação centrar-se-á mais diretamente nos aspectos técnicos de um subproblema específico: como facilitar a leitura de L1 a partir de L2, L2 a partir de L1 ou uma L2 a partir de outra L2. A resolução deste problema é crucial para a implementação de uma arquitetura de separação de activos / keystore, mas também tem casos de utilização valiosos noutras áreas, nomeadamente a otimização de chamadas fiáveis entre L2s, incluindo casos de utilização como a movimentação de activos entre L1 e L2s.
Leituras prévias recomendadas
- Publicação sobre as três transições
- Ideias da equipa Safe sobre a detenção de activos em várias cadeias
- Porque é que precisamos de uma adoção generalizada das carteiras de recuperação social
- ZK-SNARKs e algumas aplicações de privacidade
- Dankrad sobre os compromissos da KZG
- Árvores de madeira
Índice
- Qual é o objetivo?
- Como é que é uma prova de cadeia cruzada?
- Que tipos de esquemas de prova podemos utilizar?
- Como é que o L2 aprende a raiz do estado recente do Ethereum?
- Carteiras em correntes que não são L2s
- Preservar a privacidade
- Resumo
Qual é o objetivo?
Quando as L2 se tornarem mais comuns, os utilizadores terão activos em várias L2 e, possivelmente, também em L1. Quando as carteiras de contratos inteligentes (multisig, recuperação social ou outras) se tornarem comuns, as chaves necessárias para aceder a uma conta vão mudar com o tempo e as chaves antigas terão de deixar de ser válidas. Quando estas duas coisas acontecerem, um utilizador terá de ter uma forma de alterar as chaves que têm autoridade para aceder a muitas contas que vivem em muitos locais diferentes, sem fazer um número extremamente elevado de transacções.
Em particular, precisamos de uma forma de lidar com endereços contrafactuais: endereços que ainda não foram "registados" de forma alguma na cadeia, mas que, no entanto, precisam de receber e guardar fundos de forma segura. Todos nós dependemos de endereços contrafactuais: quando utiliza o Ethereum pela primeira vez, pode gerar um endereço ETH que alguém pode utilizar para lhe pagar, sem "registar" o endereço na cadeia (o que exigiria o pagamento de txfees e, por conseguinte, já possuir algum ETH).
Com as EOAs, todos os endereços começam por ser endereços contrafactuais. Com as carteiras de contratos inteligentes, os endereços contrafactuais ainda são possíveis, em grande parte graças ao CREATE2, que lhe permite ter um endereço ETH que só pode ser preenchido por um contrato inteligente que tenha código correspondente a um determinado hash.

Algoritmo de cálculo de endereços EIP-1014 (CREATE2).
No entanto, as carteiras de contratos inteligentes introduzem um novo desafio: a possibilidade de as chaves de acesso mudarem. O endereço, que é um hash do initcode, só pode conter a chave de verificação inicial da carteira. A chave de verificação atual seria guardada no armazenamento da carteira, mas esse registo de armazenamento não se propaga magicamente para outros L2s.
Se um utilizador tiver muitos endereços em muitos L2s, incluindo endereços que (porque são contrafactuais) o L2 em que se encontra não conhece, então parece que só há uma forma de permitir que os utilizadores alterem as suas chaves: arquitetura de separação entre activos e armazenamento de chaves. Cada utilizador tem (i) um "contrato de armazenamento de chaves" (em L1 ou num L2 em particular), que armazena a chave de verificação para todas as carteiras juntamente com as regras para alterar a chave, e (ii) "contratos de carteira" em L1 e em muitos L2s, que lêem a cadeia para obter a chave de verificação.

Há duas formas de o fazer:
- Versão ligeira (verificar apenas para atualizar chaves): cada carteira armazena a chave de verificação localmente e contém uma função que pode ser chamada para verificar uma prova entre cadeias do estado atual do armazenamento de chaves e atualizar a sua chave de verificação armazenada localmente para corresponder. Quando uma carteira é utilizada pela primeira vez num determinado L2, é obrigatório chamar essa função para obter a chave de verificação atual a partir do armazenamento de chaves.
- Vantagem: utiliza provas de cadeia cruzada com moderação, pelo que não tem problemas se as provas de cadeia cruzada forem dispendiosas. Todos os fundos só podem ser gastos com as chaves actuais, pelo que continua a ser seguro.
- Desvantagem: Para alterar a chave de verificação, tem de fazer uma alteração de chave na cadeia tanto no armazenamento de chaves como em todas as carteiras já inicializadas (embora não nas contrafactuais). Isto pode custar-lhe muita gasolina.
- Versão pesada (verificação para cada tx): para cada transação é necessária uma prova de cadeia cruzada que mostre a chave atualmente no keystore.
- Vantagem: menos complexidade sistémica e a atualização do armazenamento de chaves é barata.
- Lado negativo: caro por tx, pelo que requer muito mais engenharia para tornar as provas de cadeia cruzada aceitavelmente baratas. Também não é facilmente compatível com o ERC-4337, que atualmente não suporta a leitura de objectos mutáveis entre contratos durante a validação.
Como é que é uma prova de cadeia cruzada?
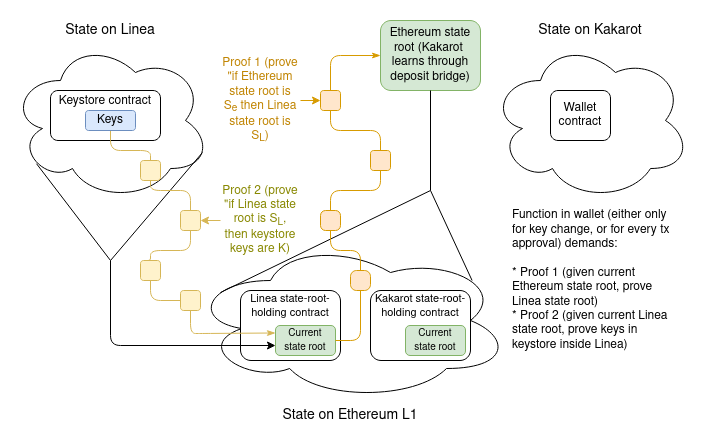
Para mostrar toda a complexidade, vamos explorar o caso mais difícil: quando o armazenamento de chaves está num L2 e a carteira está num L2 diferente. Se o armazenamento de chaves ou a carteira estiverem em L1, então apenas metade deste desenho é necessário.

Vamos assumir que o armazenamento de chaves está em Linea e a carteira está em Kakarot. Uma prova completa das chaves da carteira consiste em:
- Uma prova que demonstra a raiz do estado atual de Linea, dada a raiz do estado atual de Ethereum que Kakarot conhece
- Uma prova que comprova as chaves actuais no keystore, dado o estado atual do Linea root
Há duas questões principais de implementação complicadas aqui:
- Que tipo de provas utilizamos? (Serão provas de Merkle? outra coisa?)
- Como é que o L2 aprende a raiz do estado recente do L1 (Ethereum) (ou, como veremos, potencialmente o estado completo do L1) em primeiro lugar? E, em alternativa, como é que o L1 aprende a raiz do estado do L2?
- Em ambos os casos, qual é o tempo que decorre entre o que acontece num lado e o que pode ser provado pelo outro lado?
Que tipos de esquemas de prova podemos utilizar?
Existem cinco opções principais:
- Provas de Merkle
- ZK-SNARKs de uso geral
- Provas para fins especiais (por exemplo. com KZG)
- Provas de Verkle, que se situam algures entre as KZG e as ZK-SNARK, tanto em termos de carga de trabalho como de custo da infraestrutura.
- Não há provas e baseia-se na leitura direta do Estado
Em termos de trabalho de infraestrutura necessário e de custo para os utilizadores, classifico-os aproximadamente da seguinte forma:
"Agregação" refere-se à ideia de agregar todas as provas fornecidas pelos utilizadores dentro de cada bloco numa grande meta-prova que as combina a todas. Isto é possível para os SNARKs e para o KZG, mas não para os ramos Merkle (pode combinar um pouco os ramos Merkle, mas só poupa log(txs por bloco) / log(número total de keystores), talvez 15-30% na prática, pelo que provavelmente não vale a pena o custo).
A agregação só se torna útil quando o esquema tem um número substancial de utilizadores, por isso, realisticamente, não há problema em que uma implementação da versão 1 deixe a agregação de fora e a implemente na versão 2.
Como é que as provas de Merkle funcionam?
Esta é simples: siga diretamente o diagrama da secção anterior. Mais precisamente, cada "prova" (assumindo o caso de dificuldade máxima de provar uma L2 noutra L2) conteria:
- Um ramo de Merkle que prova a raiz de estado do L2 detentor do registo de chaves, dada a raiz de estado mais recente do Ethereum que o L2 conhece. A raiz do estado do L2 que contém o keystore é armazenada numa ranhura de armazenamento conhecida de um endereço conhecido (o contrato em L1 que representa o L2), pelo que o caminho através da árvore pode ser codificado.
- Um ramo de Merkle que prova as chaves de verificação actuais, dada a raiz de estado do L2 que contém o armazenamento de chaves. Aqui, mais uma vez, a chave de verificação é armazenada numa ranhura de armazenamento conhecida de um endereço conhecido, pelo que o caminho pode ser codificado.
Infelizmente, as provas de estado Ethereum são complicadas, mas existem bibliotecas para as verificar e, se utilizar estas bibliotecas, este mecanismo não é demasiado complicado de implementar.
O maior problema é o custo. As provas de Merkle são longas e as árvores Patricia são, infelizmente, ~3,9x mais longas do que o necessário (precisamente: uma prova de Merkle ideal numa árvore com N objectos tem 32 log2(N) bytes de comprimento e, como as árvores Patricia do Ethereum têm 16 folhas por filho, as provas para essas árvores têm 32 15 log16(N) ~= 125 log2(N) bytes de comprimento). Num estado com cerca de 250 milhões (~2²⁸) de contas, isto faz com que cada prova tenha 125 * 28 = 3500 bytes, ou seja, cerca de 56.000 gases, mais custos extra para descodificar e verificar hashes.
Duas provas juntas acabariam por custar cerca de 100 000 a 150 000 gases (sem incluir a verificação da assinatura, se esta for utilizada por transação) - significativamente mais do que os actuais 21 000 gases de base por transação. Mas a disparidade piora se a prova estiver a ser verificada em L2. A computação dentro de um L2 é barata, porque a computação é feita fora da cadeia e num ecossistema com muito menos nós do que o L1. Os dados, por outro lado, têm de ser lançados em L1. Assim, a comparação não é 21000 gás vs 150.000 gás; é 21.000 gás L2 vs 100.000 gás L1.
Pode calcular o que isto significa, se olhar para as comparações entre os custos do gás L1 e os custos do gás L2:
Atualmente, a L1 é cerca de 15-25 vezes mais cara do que a L2 para envios simples e 20-50 vezes mais cara para trocas de fichas. Os envios simples são relativamente pesados em termos de dados, mas as trocas são muito mais pesadas em termos computacionais. Por conseguinte, as trocas são uma melhor referência para aproximar o custo da computação L1 da computação L2. Tendo tudo isto em conta, se assumirmos uma relação de custo de 30x entre o custo de computação em L1 e o custo de computação em L2, isto parece implicar que colocar uma prova de Merkle em L2 custará o equivalente a talvez cinquenta transacções normais.
É claro que usar uma árvore Merkle binária pode reduzir os custos em ~4x, mas mesmo assim, na maioria dos casos, o custo será demasiado elevado - e se estivermos dispostos a fazer o sacrifício de deixar de ser compatível com a atual árvore de estados hexária do Ethereum, mais vale procurar opções ainda melhores.
Como é que as provas ZK-SNARK funcionam?
Conceptualmente, a utilização de ZK-SNARKs também é fácil de compreender: basta substituir as provas de Merkle no diagrama acima por um ZK-SNARK que prove que essas provas de Merkle existem. Um ZK-SNARK custa ~400 000 gases de computação e cerca de 400 bytes (compare: 21 000 gases e 100 bytes para uma transação básica, no futuro redutível a ~25 bytes com compressão). Assim, do ponto de vista computacional, uma ZK-SNARK custa hoje 19 vezes mais do que uma transação básica e, do ponto de vista dos dados, uma ZK-SNARK custa hoje 4x mais do que uma transação básica e 16 vezes mais do que uma transação básica poderá custar no futuro.
{kind=link}
Estes números representam uma enorme melhoria em relação às provas de Merkle, mas continuam a ser bastante dispendiosos. Há duas formas de melhorar esta situação: (i) provas KZG para fins especiais, ou (ii) agregação, semelhante à agregação ERC-4337, mas utilizando matemática mais sofisticada. Podemos analisar ambos.
Como é que as provas KZG para fins especiais funcionam?
Atenção, esta secção é muito mais matemática do que as outras secções. Isto deve-se ao facto de estarmos a ir além das ferramentas de uso geral e a construir algo de propósito especial para ser mais barato, pelo que temos de ir muito mais "debaixo do capô". Se não gosta de matemática profunda, passe diretamente para a secção seguinte.
Em primeiro lugar, recapitule o funcionamento das autorizações KZG:
- Podemos representar um conjunto de dados [D_1 ... D_n] com uma prova KZG de um polinómio derivado dos dados: especificamente, o polinómio P em que P(w) = D_1, P(w²) = D_2 ... P(wⁿ) = D_n. w aqui é uma "raiz da unidade", um valor em que wᴺ = 1 para um domínio de avaliação de dimensão N (tudo isto é feito num campo finito).
- Para nos "comprometermos" com P, criamos um ponto da curva elíptica com(P) = P₀ G + P₁ S₁ + ... + Pₖ * Sₖ. Aqui:
- G é o ponto gerador da curva
- Pᵢ é o coeficiente de i-ésimo grau do polinómio P
- Sᵢ é o i-ésimo ponto na configuração de confiança
- Para provar que P(z) = a, criamos um polinómio quociente Q = (P - a) / (X - z), e criamos um compromisso com(Q) para ele. Só é possível criar um polinómio deste tipo se P(z) for efetivamente igual a a.
- Para verificar uma prova, verificamos a equação Q * (X - z) = P - a fazendo uma verificação da curva elíptica na prova com(Q) e o compromisso polinomial com(P): verificamos e(com(Q), com(X - z)) ?= e(com(P) - com(a), com(1))
Algumas propriedades-chave que é importante compreender são:
- Uma prova é apenas o valor com(Q), que é de 48 bytes
- com(P₁) + com(P₂) = com(P₁ + P₂)
- Isto também significa que pode "editar" um valor numa autorização existente. Suponha que sabemos que D_i é atualmente a, que queremos definir para b e que o compromisso existente com D é com(P). Um compromisso com "P, mas com P(wⁱ) = b, e sem outras avaliações alteradas", então definimos com(novo_P) = com(P) + (b-a) * com(Lᵢ), onde Lᵢ é a o "polinómio de Lagrange" que é igual a 1 em wⁱ e 0 nos outros pontos de wʲ.
- Para realizar estas actualizações de forma eficiente, todos os N compromissos com os polinómios de Lagrange (com(Lᵢ)) podem ser pré-calculados e armazenados por cada cliente. No interior de um contrato na cadeia pode ser demasiado armazenar todos os N compromissos, por isso, em vez disso, pode fazer um compromisso KZG para o conjunto de valores com(L_i) (ou hash(com(L_i)), por isso, sempre que alguém precisar de atualizar a árvore na cadeia pode simplesmente fornecer o com(L_i) apropriado com uma prova da sua correção.
Assim, temos uma estrutura em que podemos simplesmente continuar a acrescentar valores ao final de uma lista sempre crescente, embora com um certo limite de tamanho (realisticamente, centenas de milhões poderiam ser viáveis). Em seguida, usamos isso como nossa estrutura de dados para gerenciar (i) um compromisso com a lista de chaves em cada L2, armazenado nesse L2 e espelhado para L1, e (ii) um compromisso com a lista de compromissos de chave L2, armazenado no Ethereum L1 e espelhado para cada L2.
Manter os compromissos actualizados pode tornar-se parte da lógica do núcleo L2 ou pode ser implementado sem alterações no protocolo do núcleo L2 através de pontes de depósito e retirada.

Uma prova completa exigiria, portanto:
- A última com(lista de chaves) no L2 que contém o keystore (48 bytes)
- Prova KZG de que com(key list) é um valor dentro de com(mirror_list), o compromisso com a lista de todos os compromissos da lista de chaves (48 bytes)
- KZG prova da sua chave em com(lista de chaves) (48 bytes, mais 4 bytes para o índice)
Na verdade, é possível juntar as duas provas KZG numa só, pelo que obtemos um tamanho total de apenas 100 bytes.
Note uma subtileza: como a lista de chaves é uma lista, e não um mapa chave/valor como o estado, a lista de chaves terá de atribuir posições sequencialmente. O contrato de compromisso de chave conteria o seu próprio registo interno, mapeando cada keystore para um ID, e para cada chave armazenaria hash(key, endereço do keystore) em vez de apenas key, para comunicar inequivocamente a outros L2s de que keystore uma determinada entrada está a falar.
A vantagem desta técnica é que funciona muito bem em L2. Os dados são 100 bytes, ~4x mais curtos do que um ZK-SNARK e muito mais curtos do que uma prova de Merkle. O custo de cálculo é, em grande parte, um cheque de emparelhamento de tamanho 2, ou cerca de 119 000 gases. Em L1, os dados são menos importantes do que a computação, pelo que, infelizmente, a KZG é um pouco mais cara do que as provas de Merkle.
Como é que as árvores Verkle funcionam?
As árvores de Verkle envolvem essencialmente o empilhamento de compromissos KZG (ou compromissos IPA, que podem ser mais eficientes e usar criptografia mais simples) uns sobre os outros: para armazenar 2⁴⁸ valores, pode fazer um compromisso KZG com uma lista de 2²⁴ valores, cada um dos quais é um compromisso KZG com 2²⁴ valores. As árvores de tornozelo estão a ser <a href="https://notes.ethereum.org/@vbuterin/verkle_tree_eip"> fortemente considerada para a árvore de estados do Ethereum, porque as árvores Verkle podem ser usadas para guardar mapas de valores-chave e não apenas listas (basicamente, pode fazer uma árvore de tamanho-2²⁵⁶ mas começá-la vazia, só preenchendo partes específicas da árvore quando precisar efetivamente de as preencher).

O aspeto de uma árvore Verkle. Na prática, pode dar a cada nó uma largura de 256 == 2⁸ para árvores baseadas em IPA, ou 2²⁴ para árvores baseadas em KZG.
As provas em árvores de Verkle são um pouco mais longas do que em KZG; podem ter algumas centenas de bytes. São também difíceis de verificar, especialmente se tentar agregar muitas provas numa só.
Realisticamente, as árvores de Verkle devem ser consideradas como árvores de Merkle, mas mais viáveis sem SNARKing (devido aos custos mais baixos dos dados) e mais baratas com SNARKing (devido aos custos mais baixos do provador).
A maior vantagem das árvores de Verkle é a possibilidade de harmonizar as estruturas de dados: As provas de Verkle podem ser utilizadas diretamente sobre o estado L1 ou L2, sem estruturas de sobreposição e utilizando exatamente o mesmo mecanismo para L1 e L2. Quando os computadores quânticos se tornarem um problema, ou quando a prova dos ramos de Merkle se tornar suficientemente eficiente, as árvores de Verkle podem ser substituídas no local por uma árvore de hash binária com uma função de hash adequada ao SNARK.
Agregação
Se N utilizadores fizerem N transacções (ou, mais realisticamente, N ERC-4337 UserOperations) que precisem de provar N reivindicações entre cadeias, podemos poupar muito gás agregando essas provas: o construtor que combinaria essas transacções num bloco ou num pacote que vai para um bloco pode criar uma única prova que prove todas essas reivindicações simultaneamente.
Isto pode significar:
- Uma prova ZK-SNARK de N ramos de Merkle
- Uma KZG multi-prova
- Uma multiprova Verkle (ou um ZK-SNARK de uma multiprova)
Nos três casos, as provas custariam apenas algumas centenas de milhares de euros cada. O construtor teria de fazer um destes em cada L2 para os utilizadores desse L2; assim, para que a sua construção seja útil, o esquema como um todo tem de ter uma utilização suficiente para que haja frequentemente pelo menos algumas transacções dentro do mesmo bloco em vários L2s principais.
Se forem utilizados ZK-SNARKs, o principal custo marginal é simplesmente a "lógica comercial" da passagem de números entre contratos, ou seja, talvez alguns milhares de gás L2 por utilizador. Se forem utilizadas provas múltiplas KZG, o provador teria de acrescentar 48 gases por cada L2 que contenha uma chave de armazenamento utilizada nesse bloco, pelo que o custo marginal do esquema por utilizador acrescentaria mais ~800 gases L1 por L2 (não por utilizador). Mas estes custos são muito inferiores aos custos da não agregação, que implicam inevitavelmente mais de 10 000 gases L1 e centenas de milhares de gases L2 por utilizador. Para as árvores de Verkle, pode utilizar diretamente as multi-provas de Verkle, adicionando cerca de 100-200 bytes por utilizador, ou pode fazer um ZK-SNARK de uma multi-prova de Verkle, que tem custos semelhantes aos ZK-SNARKs de ramos de Merkle, mas é significativamente mais barato de provar.
Do ponto de vista da implementação, é provavelmente melhor que os agrupadores agreguem provas de cadeia cruzada através da norma de abstração de conta ERC-4337. O ERC-4337 já tem um mecanismo que permite aos construtores agregar partes de UserOperations de forma personalizada. Existe mesmo uma <a href="https://hackmd.io/@voltrevo/BJ0QBy3zi"> implementação deste processo para a agregação de assinaturas BLS, que poderá reduzir os custos do gás em L2 entre 1,5x e 3x, dependendo das outras formas de compressão incluídas.

Diagrama retirado de <a href="https://hackmd.io/@voltrevo/BJ0QBy3zi"> Post de implementação da carteira BLS mostrando o fluxo de trabalho das assinaturas agregadas BLS numa versão anterior do ERC-4337. O fluxo de trabalho de agregação de provas entre cadeias será provavelmente muito semelhante.
Leitura direta do estado
Uma última possibilidade, e apenas utilizável para L2 que lê L1 (e não L1 que lê L2), é modificar L2s para lhes permitir fazer chamadas estáticas a contratos em L1 diretamente.
Isto poderia ser feito com um opcode ou uma pré-compilação, que permite chamadas para L1 onde você fornece o endereço de destino, gás e calldata, e retorna a saída, embora porque estas chamadas são chamadas estáticas elas não podem realmente mudar qualquer estado L1. Os L2 têm de ter conhecimento do L1 para processar os depósitos, pelo que não há nada de fundamental que impeça a sua implementação; trata-se sobretudo de um desafio de implementação técnica (ver: esta RFP do Optimism para suportar chamadas estáticas para o L1).
Repare que se o keystore estiver em L1 e os L2s integrarem a funcionalidade de chamada estática de L1, então não são necessárias quaisquer provas! No entanto, se os L2s não integrarem chamadas estáticas L1, ou se o keystore estiver no L2 (o que poderá eventualmente ter de acontecer, uma vez que o L1 se torna demasiado dispendioso para os utilizadores o utilizarem, nem que seja um pouco), então serão necessárias provas.
Como é que o L2 aprende a raiz do estado recente do Ethereum?
Todos os esquemas acima requerem que o L2 aceda ou à raiz do estado L1 recente, ou a todo o estado L1 recente. Felizmente, todos os L2s já têm alguma funcionalidade para aceder ao estado recente do L1. Isto deve-se ao facto de necessitarem dessa funcionalidade para processar as mensagens provenientes de L1 para L2, nomeadamente os depósitos.
E, de facto, se um L2 tiver uma funcionalidade de depósito, então pode usar esse L2 tal como está para mover raízes de estado de L1 para um contrato no L2: basta que um contrato em L1 chame o opcode BLOCKHASH e o passe para L2 como uma mensagem de depósito. O cabeçalho completo do bloco pode ser recebido, e a sua raiz de estado extraída, no lado L2. No entanto, seria muito melhor que cada L2 tivesse uma forma explícita de aceder diretamente ao estado L1 recente completo ou às raízes do estado L1 recente.
O principal desafio da otimização da forma como os L2 recebem as raízes recentes do estado L1 é conseguir simultaneamente segurança e baixa latência:
- Se os L2s implementarem a funcionalidade de "leitura direta de L1" de uma forma preguiçosa, lendo apenas as raízes de estado L1 finalizadas, então o atraso será normalmente de 15 minutos, mas no caso extremo de fugas de inatividade (que tem de tolerar), o atraso pode ser de várias semanas.
- Os L2s podem ser concebidos para ler raízes de estado L1 muito mais recentes, mas como o L1 pode reverter (mesmo com a finalidade de slot único, as reversões podem ocorrer durante fugas de inatividade), o L2 teria de ser capaz de reverter também. Trata-se de um desafio técnico do ponto de vista da engenharia de software, mas, pelo menos, o Optimism já tem essa capacidade.
- Se utilizar a ponte de depósito para trazer as raízes do estado L1 para o L2, então a viabilidade económica simples pode exigir um longo período de tempo entre as actualizações do depósito: se o custo total de um depósito for 100.000 gas, e assumirmos que o ETH está a $1800, e as taxas estão a 200 gwei, e as raízes L1 são trazidas para o L2 uma vez por dia, isso seria um custo de $36 por L2 por dia, ou $13148 por L2 por ano para manter o sistema. Com um atraso de uma hora, esse valor sobe para $315.569 por L2 e por ano. Na melhor das hipóteses, um fluxo constante de utilizadores ricos e impacientes cobre as taxas de atualização e mantém o sistema atualizado para todos os outros. Na pior das hipóteses, algum ator altruísta teria de pagar por isso.
- Os "oráculos" (pelo menos, o tipo de tecnologia a que algumas pessoas chamam "oráculos") não são uma solução aceitável neste caso: a gestão de chaves de carteiras é uma funcionalidade de baixo nível muito crítica em termos de segurança, pelo que deve depender, no máximo, de algumas peças de uma infraestrutura de baixo nível muito simples e criptograficamente fiável.
Além disso, na direção oposta (L1s lendo L2):
- Nos rollups optimistas, as raízes estatais demoram uma semana a chegar a L1 devido ao atraso da prova de fraude. No caso dos rollups ZK, são necessárias algumas horas, por enquanto, devido a uma combinação de tempos de prova e limites económicos, embora a tecnologia futura venha a reduzir esse tempo.
- As pré-confirmações (de sequenciadores, atestadores, etc.) não são uma solução aceitável para a leitura de L1 em L2. A gestão de carteiras é uma funcionalidade de baixo nível muito crítica em termos de segurança, pelo que o nível de segurança da comunicação L2 -> L1 deve ser absoluto: nem sequer deve ser possível criar uma raiz de estado L1 falsa, apropriando-se do conjunto de validadores L2. As únicas raízes de estado em que o L1 deve confiar são as raízes de estado que foram aceites como finais pelo contrato de retenção de raízes de estado do L2 no L1.
Algumas destas velocidades para operações sem confiança entre cadeias são inaceitavelmente lentas para muitos casos de utilização definidos; para esses casos, precisa de pontes mais rápidas com modelos de segurança mais imperfeitos. No entanto, para o caso de utilização de atualização de chaves de carteira, os atrasos mais longos são mais aceitáveis: não está a atrasar as transacções em horas, está a atrasar as alterações de chaves. Terá apenas de manter as chaves antigas por mais tempo. Se está a mudar de chaves porque as chaves são roubadas, então tem um período significativo de vulnerabilidade, mas isso pode ser atenuado, por exemplo, por carteiras com uma função de congelamento.
Em última análise, a melhor solução para minimizar a latência é que os L2s implementem a leitura direta das raízes de estado L1 de uma forma optimizada, em que cada bloco L2 (ou o registo de computação da raiz de estado) contenha um ponteiro para o bloco L1 mais recente, pelo que, se L1 reverter, L2 também pode reverter. Os contratos de armazenamento de chaves devem ser colocados na rede principal ou em L2s que são ZK-rollups e, portanto, podem ser rapidamente transferidos para L1.

Os blocos da cadeia L2 podem ter dependências não só de blocos L2 anteriores, mas também de um bloco L1. Se o L1 reverter para além dessa ligação, o L2 também reverte. Vale a pena notar que esta é também a forma como uma versão anterior (pré-Dank) do sharding foi concebida para funcionar; veja aqui o código.
De quanta ligação ao Ethereum precisa outra cadeia para manter carteiras cujos armazenamentos de chaves estão enraizados no Ethereum ou num L2?
Surpreendentemente, não é assim tanto. Na verdade, nem sequer precisa de ser um rollup: se for um L3, ou um validium, então não há problema em manter as carteiras aí, desde que mantenha os keystores no L1 ou num rollup ZK. O que você precisa é que a cadeia tenha acesso direto às raízes do estado do Ethereum, e um compromisso técnico e social para estar disposto a reorgar se o Ethereum reorgar, e hard fork se o Ethereum hard forks.
Um problema de investigação interessante é identificar até que ponto é possível que uma cadeia tenha esta forma de ligação a várias outras cadeias (por exemplo, a cadeia de distribuição de alimentos). Ethereum e Zcash). Fazê-lo de forma ingénua é possível: a sua cadeia pode concordar em reorganizar-se se o Ethereum ou o Zcash se reorganizarem (e fazer um hard fork se o Ethereum ou o Zcash se reorganizarem), mas nesse caso os seus operadores de nós e a sua comunidade em geral têm o dobro das dependências técnicas e políticas. Assim, esta técnica pode ser utilizada para se ligar a algumas outras cadeias, mas a um custo crescente. Os esquemas baseados em pontes ZK têm propriedades técnicas atractivas, mas têm como principal fraqueza o facto de não serem resistentes a ataques de 51% ou a bifurcações difíceis. Poderá haver soluções mais inteligentes.
Preservar a privacidade
Idealmente, também queremos preservar a privacidade. Se tiver muitas carteiras que são geridas pelo mesmo repositório de chaves, queremos certificar-nos disso:
- Não é do conhecimento público que essas carteiras estão todas ligadas entre si.
- Os guardiões da recuperação social não ficam a saber quais são os endereços que estão a guardar.
Isto cria alguns problemas:
- Não podemos utilizar diretamente as provas de Merkle, porque não preservam a privacidade.
- Se utilizarmos KZG ou SNARKs, então a prova precisa de fornecer uma versão cega da chave de verificação, sem revelar a localização da chave de verificação.
- Se utilizarmos a agregação, então o agregador não deve saber a localização em texto simples; em vez disso, o agregador deve receber provas cegas e ter uma forma de as agregar.
- Não podemos utilizar a "versão light" (utilizar provas de cadeia cruzada apenas para atualizar chaves), porque cria uma fuga de privacidade: se muitas carteiras forem actualizadas ao mesmo tempo devido a um procedimento de atualização, o momento da atualização deixa escapar a informação de que essas carteiras estão provavelmente relacionadas. Por isso, temos de utilizar a "versão pesada" (provas de cadeia cruzada para cada transação).
Com os SNARKs, as soluções são concetualmente fáceis: as provas escondem informação por defeito e o agregador precisa de produzir um SNARK recursivo para provar os SNARKs.
Atualmente, o principal desafio desta abordagem é o facto de a agregação exigir que o agregador crie um SNARK recursivo, o que é bastante lento.
Com KZG, podemos utilizar <a href="https://notes.ethereum.org/@vbuterin/non_index_revealing_proof"> this trabalho sobre provas KZG não reveladoras de índices (ver também: uma versão mais formalizada desse trabalho no artigo de Caulk) como ponto de partida. A agregação de provas cegas é, no entanto, um problema em aberto que requer mais atenção.
A leitura direta de L1 a partir do interior de L2, infelizmente, não preserva a privacidade, embora a implementação da funcionalidade de leitura direta continue a ser muito útil, tanto para minimizar a latência como devido à sua utilidade para outras aplicações.
Resumo
- Para ter carteiras de recuperação social entre cadeias, o fluxo de trabalho mais realista é uma carteira que mantém um armazenamento de chaves num local, e carteiras em muitos locais, onde a carteira lê o armazenamento de chaves (i) para atualizar a sua visão local da chave de verificação, ou (ii) durante o processo de verificação de cada transação.
- Um ingrediente chave para tornar isto possível são as provas de cadeia cruzada. Temos de otimizar estas provas com afinco. As ZK-SNARKs, à espera das provas de Verkle, ou uma solução KZG personalizada, parecem ser as melhores opções.
- A longo prazo, os protocolos de agregação em que os agrupadores geram provas agregadas como parte da criação de um pacote de todas as UserOperations que foram submetidas pelos utilizadores serão necessários para minimizar os custos. Provavelmente, isto deve ser integrado no ecossistema ERC-4337, embora seja provável que sejam necessárias alterações ao ERC-4337.
- Os L2s devem ser optimizados para minimizar a latência da leitura do estado L1 (ou pelo menos a raiz do estado) a partir do interior do L2. Os L2s que lêem diretamente o estado L1 são ideais e podem poupar espaço de prova.
- As carteiras não podem estar apenas em L2s; também pode colocar carteiras em sistemas com níveis mais baixos de ligação ao Ethereum (L3s, ou mesmo cadeias separadas que apenas concordam em incluir raízes de estado Ethereum e reorg ou hard fork quando o Ethereum reorg ou hardforks).
- No entanto, os armazenamentos de chaves devem estar em L1 ou no ZK-rollup L2 de alta segurança. Estar em L1 poupa muita complexidade, embora a longo prazo até isso possa ser demasiado caro, daí a necessidade de keystores em L2.
- A preservação da privacidade exigirá trabalho adicional e tornará algumas opções mais difíceis. No entanto, devemos provavelmente avançar para soluções que preservem a privacidade de qualquer forma e, pelo menos, certificarmo-nos de que tudo o que propomos é compatível com a preservação da privacidade.
Declaração de exoneração de responsabilidade:
- Este artigo foi reimpresso de[vitalik], Todos os direitos de autor pertencem ao autor original[Vitalik Buterin]. Se houver objecções a esta reimpressão, contacte a equipa da Gate Learn, que tratará prontamente do assunto.
- Declaração de exoneração de responsabilidade: Os pontos de vista e opiniões expressos neste artigo são da exclusiva responsabilidade do autor e não constituem um conselho de investimento.
- As traduções do artigo para outras línguas são efectuadas pela equipa Gate Learn. A menos que seja mencionado, é proibido copiar, distribuir ou plagiar os artigos traduzidos.
Partilhar
Conteúdos
Leituras prévias recomendadas
Índice
Qual é o objetivo?
Como é que é uma prova de cadeia cruzada?
Que tipos de esquemas de prova podemos utilizar?
Como é que o L2 aprende a raiz do estado recente do Ethereum?
De quanta ligação ao Ethereum necessita outra cadeia para manter carteiras cujos armazenamentos de chaves estão enraizados no Ethereum ou num L2?
Preservar a privacidade
Resumo


Artigos relacionados

Como Aposta ETH

Tudo o que precisa saber sobre o Quantitative Strategy Trading

O que é o EtherVista, o "Novo Padrão para DEX" auto-proclamado?

O que é a fusão?

O que é o Ethereum 2.0? Entender a Mesclagem
