OpenAI突襲發布GPT-5.5模型,主打最強大且直覺的寫程式與跨工具操作能力,本文整理GPT-5.5與Claude Opus 4.7與Gemini 3.1 Pro等主流模型的效能比較。OpenAI的GPT-5.5模型來了!特色一次看------------------------AI 巨頭 OpenAI 在台灣時間 4 月 24 日凌晨,突襲推出全新 GPT-5.5 模型,宣稱是至今最聰明且操作最直覺的 AI 系統。**OpenAI 表示,GPT-5.5 模型具備強大 AI 代理人寫程式能力,擅長處理程式碼除 Bug、線上研究及跨工具操作。**與前代的 GPT-5.4 相比,GPT-5.5 維持相同運算延遲水準,能以更少的標記完成任務。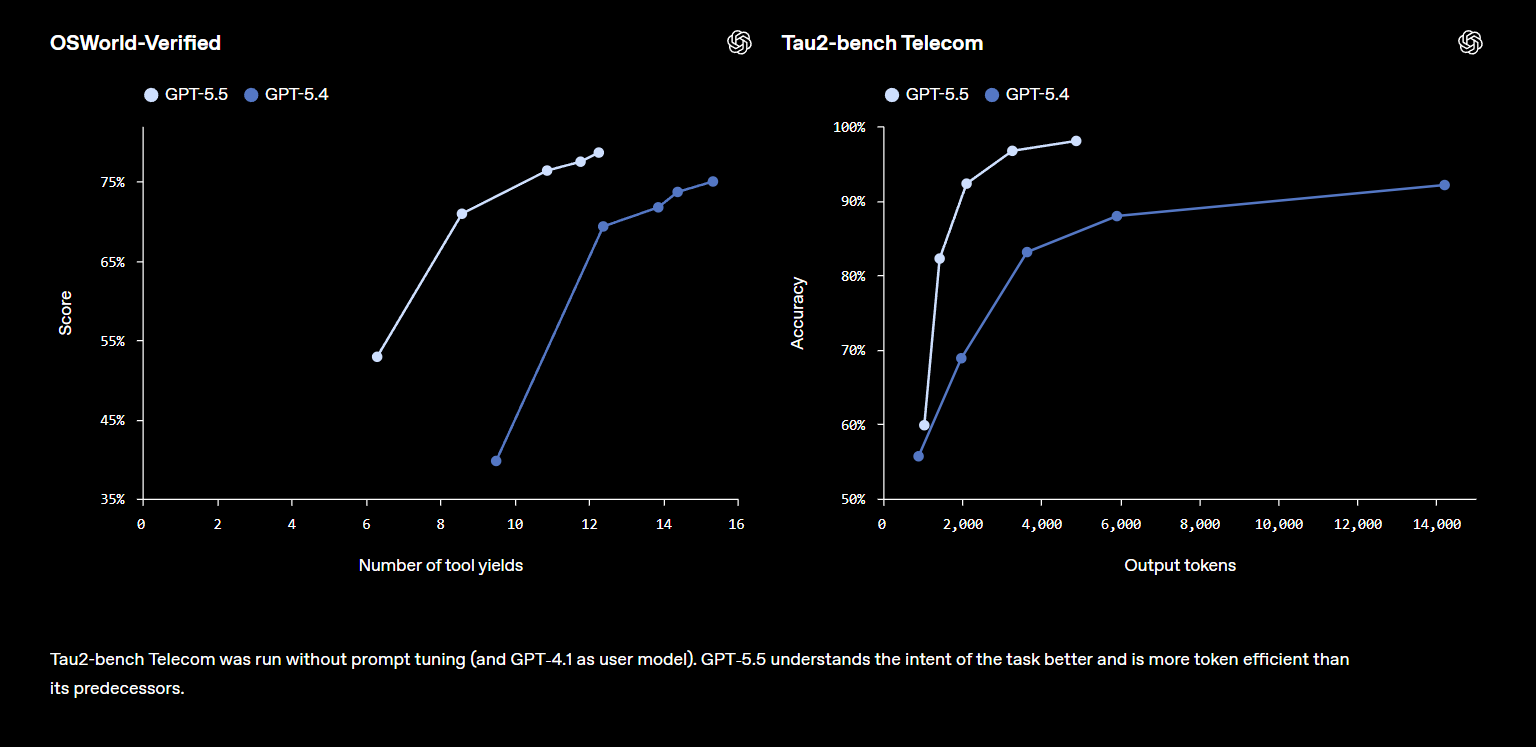OpenAI 總裁 Greg Brockman 指出,新模型是邁向直覺運算的重要進展,也是打造結合 ChatGPT、Codex 與 AI 瀏覽器的超級應用程式的關鍵一步。GPT-5.5模型費用方案與使用權限------------------即日起,**ChatGPT 的 Plus、Pro、Business 與 Enterprise 方案用戶,以及 Codex 用戶都可以使用 GPT-5.5,進階版 GPT-5.5 Pro 則提供給 Pro、Business 與 Enterprise 用戶。**在 API 定價方面,GPT-5.5 輸入 Token 費用為每 100 萬個 5 美元,輸出為每 100 萬個 30 美元。GPT-5.5 Pro 輸入 Token 為每 100 萬個 30 美元,輸出為每 100 萬個 180 美元。不過有趣的是,GPT-5.5 模型發表的時間點,恰逢馬斯克(Elon Musk)與 OpenAI 執行長奧特曼(Sam Altman)即將在法庭訴訟之際,引發外界關注。GPT-5.5基準測試表現:優勢與劣勢分析---------------------在效能基準測試(Benchmark)中,GPT-5.5 展現技術優勢,但部分領域仍面臨挑戰。**根據 OpenAI 官方數據,GPT-5.5 模型在評估複雜命令列的 Terminal-Bench 2.0 測試裡,準確率達到 82.7%;在評估知識工作的 GDPval 測試中,則取得 84.9% 高分,顯示日常辦公具高度實用價值。**GPT-5.5 在解決 GitHub 實際問題的 SWE-Bench Pro 公開測試成績為 58.6%,微幅落後 Anthropic 推出的 Claude Opus 4.7 的 64.3%。OpenAI 雖註明測試可能受模型記憶效應影響,但仍反映 GPT-5.5 在特定開發除 Bug 存在劣勢。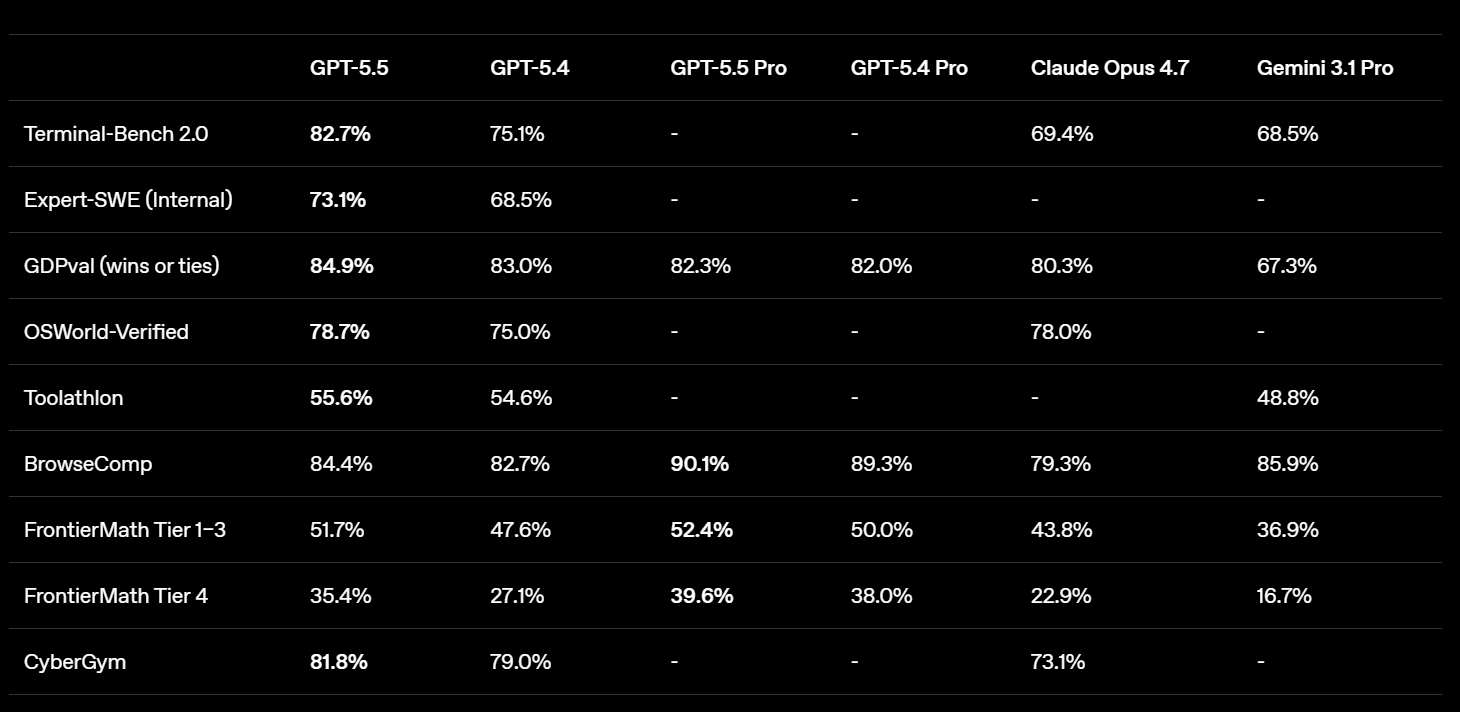圖源:OpenAIGPT-5.5基準測試表現:優勢與劣勢分析資安領域方面,Anthropic 日前推出主打強大資安的 Claude Mythos Preview 模型,而 GPT-5.5 雖提升防禦能力,目前僅透過特定管道讓認證企業用於基礎設施防護。主流模型比較:GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro---------------------------------------------### GPT-5.5與Claude Opus 4.7數據比較綜合 OpenAI 官方與 ITmedia 的測試資料,在測驗實際電腦作業環境的 OSWorld-Verified 項目中,GPT-5.5 得分 78.7%,微幅領先 Claude Opus 4.7 的 78.0%。在進階邏輯運算與工具協作的 BrowseComp 測試中,GPT-5.5 取得 84.4% 成績,勝過 Claude Opus 4.7 的 79.3%;在檢驗高等數學能力的 FrontierMath Tier 1 至 3 測試中,GPT-5.5 以 51.7% 超越 Claude Opus 4.7 的 43.8%。### GPT-5.5與Gemini 3.1 Pro數據比較與 Gemini 3.1 Pro 比較,GPT-5.5 在多數專業測試維持領先。在 GDPval 知識工作測試中,GPT-5.5 以 84.9% 超越 Gemini 3.1 Pro 的 67.3%。針對外部工具使用的 Toolathlon 評估中,GPT-5.5 獲得 55.6% 分數,優於 Gemini 3.1 Pro 的 48.8%。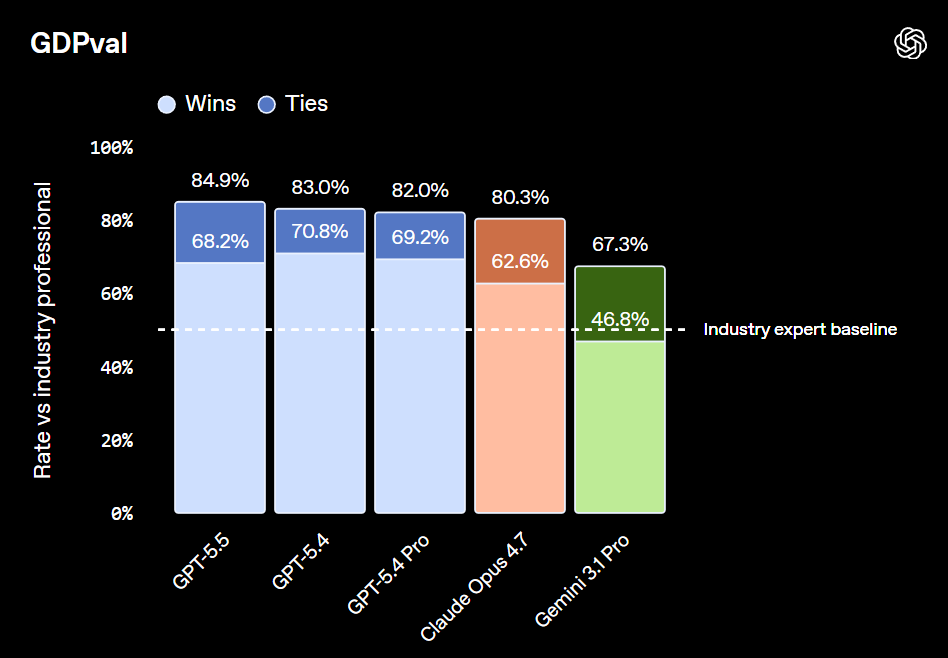圖源:OpenAIGPT-5.5與Gemini 3.1 Pro數據比較在無工具輔助的 MMMU Pro 多模態測試中,GPT-5.5 成績為 81.2%,Gemini 3.1 Pro 為 80.5%,兩者表現十分接近。GPT-5.5是為IPO上市鋪路?-----------------OpenAI 研究長 Mark Chen 指出,**GPT-5.5 在科學與技術研究流程上帶來實質的提升,未來有望協助科學家在藥物發現等領域加速研究腳步。**外媒《The Verge》指出,這款新模型的問世,反映了 OpenAI 與 Anthropic 為了爭奪企業級 AI 工具市場的主導權,並為今年稍晚可能進行的首次公開募股上市(IPO)鋪路,雙方正展開日益白熱化的角力。延伸閱讀: ChatGPT Images 2.0怎麼用?實測牛肉麵菜單、雜誌封面、多國語言科普效果
GPT 5.5モデル発表:研究開発プログラミングに特化!Claude Opus 4.7との違いを一度比較してみよう
OpenAI突襲發布GPT-5.5模型,主打最強大且直覺的寫程式與跨工具操作能力,本文整理GPT-5.5與Claude Opus 4.7與Gemini 3.1 Pro等主流模型的效能比較。
OpenAI的GPT-5.5模型來了!特色一次看
AI 巨頭 OpenAI 在台灣時間 4 月 24 日凌晨,突襲推出全新 GPT-5.5 模型,宣稱是至今最聰明且操作最直覺的 AI 系統。
OpenAI 表示,GPT-5.5 模型具備強大 AI 代理人寫程式能力,擅長處理程式碼除 Bug、線上研究及跨工具操作。
與前代的 GPT-5.4 相比,GPT-5.5 維持相同運算延遲水準,能以更少的標記完成任務。
OpenAI 總裁 Greg Brockman 指出,新模型是邁向直覺運算的重要進展,也是打造結合 ChatGPT、Codex 與 AI 瀏覽器的超級應用程式的關鍵一步。
GPT-5.5模型費用方案與使用權限
即日起,ChatGPT 的 Plus、Pro、Business 與 Enterprise 方案用戶,以及 Codex 用戶都可以使用 GPT-5.5,進階版 GPT-5.5 Pro 則提供給 Pro、Business 與 Enterprise 用戶。
在 API 定價方面,GPT-5.5 輸入 Token 費用為每 100 萬個 5 美元,輸出為每 100 萬個 30 美元。GPT-5.5 Pro 輸入 Token 為每 100 萬個 30 美元,輸出為每 100 萬個 180 美元。
不過有趣的是,GPT-5.5 模型發表的時間點,恰逢馬斯克(Elon Musk)與 OpenAI 執行長奧特曼(Sam Altman)即將在法庭訴訟之際,引發外界關注。
GPT-5.5基準測試表現:優勢與劣勢分析
在效能基準測試(Benchmark)中,GPT-5.5 展現技術優勢,但部分領域仍面臨挑戰。
根據 OpenAI 官方數據,GPT-5.5 模型在評估複雜命令列的 Terminal-Bench 2.0 測試裡,準確率達到 82.7%;在評估知識工作的 GDPval 測試中,則取得 84.9% 高分,顯示日常辦公具高度實用價值。
GPT-5.5 在解決 GitHub 實際問題的 SWE-Bench Pro 公開測試成績為 58.6%,微幅落後 Anthropic 推出的 Claude Opus 4.7 的 64.3%。
OpenAI 雖註明測試可能受模型記憶效應影響,但仍反映 GPT-5.5 在特定開發除 Bug 存在劣勢。
圖源:OpenAIGPT-5.5基準測試表現:優勢與劣勢分析
資安領域方面,Anthropic 日前推出主打強大資安的 Claude Mythos Preview 模型,而 GPT-5.5 雖提升防禦能力,目前僅透過特定管道讓認證企業用於基礎設施防護。
主流模型比較:GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro
GPT-5.5與Claude Opus 4.7數據比較
綜合 OpenAI 官方與 ITmedia 的測試資料,在測驗實際電腦作業環境的 OSWorld-Verified 項目中,GPT-5.5 得分 78.7%,微幅領先 Claude Opus 4.7 的 78.0%。
在進階邏輯運算與工具協作的 BrowseComp 測試中,GPT-5.5 取得 84.4% 成績,勝過 Claude Opus 4.7 的 79.3%;在檢驗高等數學能力的 FrontierMath Tier 1 至 3 測試中,GPT-5.5 以 51.7% 超越 Claude Opus 4.7 的 43.8%。
GPT-5.5與Gemini 3.1 Pro數據比較
與 Gemini 3.1 Pro 比較,GPT-5.5 在多數專業測試維持領先。在 GDPval 知識工作測試中,GPT-5.5 以 84.9% 超越 Gemini 3.1 Pro 的 67.3%。
針對外部工具使用的 Toolathlon 評估中,GPT-5.5 獲得 55.6% 分數,優於 Gemini 3.1 Pro 的 48.8%。
圖源:OpenAIGPT-5.5與Gemini 3.1 Pro數據比較
在無工具輔助的 MMMU Pro 多模態測試中,GPT-5.5 成績為 81.2%,Gemini 3.1 Pro 為 80.5%,兩者表現十分接近。
GPT-5.5是為IPO上市鋪路?
OpenAI 研究長 Mark Chen 指出,GPT-5.5 在科學與技術研究流程上帶來實質的提升,未來有望協助科學家在藥物發現等領域加速研究腳步。
外媒《The Verge》指出,這款新模型的問世,反映了 OpenAI 與 Anthropic 為了爭奪企業級 AI 工具市場的主導權,並為今年稍晚可能進行的首次公開募股上市(IPO)鋪路,雙方正展開日益白熱化的角力。
延伸閱讀:
ChatGPT Images 2.0怎麼用?實測牛肉麵菜單、雜誌封面、多國語言科普效果