
Система AI для пам’яті MemPalace, яку розробляє Miйла Йовович, заявляє, що тести набрали ідеальні бали й швидко стала вірусною, але спільнота викрила, що тести нібито містять шахрайство та маніпуляції з даними. Під час практичної перевірки виявили, що ефект перебільшений і є багато помилок; команда визнала недоліки та вже працює над їх виправленням.
Міла Йовович створила AI-«палац пам’яті», що викликало інтерес з боку зовнішніх
У вчорашньому (4/7) великому новинному блоці в AI-спільноті йдеться про те, що голлівудська акторка Міла Йовович (Milla Jovovich), відома за «Оселя зла» та «П’ятий елемент», разом із розробником Беном Сігманом (Ben Sigman) за допомогою Claude Code створили «MemPalace» — відкриту AI-систему пам’яті.
Поширилась версія про «голлівудську зірку, яка в кросовері зробила проєкт на 100 балів», і станом на сьогодні MemPalace на GitHub має понад 20 тисяч зірок, але дуже швидко це викликало сумніви в середовищі розробників: це справді щось вартісне чи просто розкрутка?
Спершу пояснимо мотивацію появи MemPalace. У офіційній документації зазначено, що хотіли вирішити проблему: використані в AI-системах користувацькі діалоги, процеси ухвалення рішень та обговорення архітектури зазвичай зникають після завершення робочої сесії, через що кілька місяців праці падають до нуля.
Щоб вирішити цю проблему, MemPalace використовує просторову архітектуру для збереження спогадів: інформацію чітко класифікують на крила, що представляють персонал або проєкти, а також у різних рівнях структури — коридорах, кімнатах і шухлядах, щоб зберігати оригінальний текст діалогу для подальшого семантичного пошуку.
Розробницька команда стверджує, що MemPalace отримала 100% у довготривалому оціночному базисі пам’яті LongMemEval, і досягла точності 96,6% без виклику будь-яких зовнішніх API, а також може повністю працювати локально, не потребуючи підписки на хмарні сервіси, і має вбудовану заявлену систему діалектів AAAK, здатну забезпечити 30-кратне безповоротне стиснення.
Джерело зображення: GitHub Голлівудська зірка Міла Йовович створила AI-«палац пам’яті», що привернуло увагу ззовні
Колеги й спільнота разом поставили під сумнів, а також вказали на недоліки в методі тестування та рекламі
Втім, результати MemPalace з «ідеальним» LongMemEval дуже швидко викликали заперечення в колег.
PenfieldLabs, яка так само розробляє AI-системи пам’яті, зазначила, що заявити про 100% на датасеті LoCoMo математично неможливо, оскільки стандартні відповіді для цього датасету самі по собі містять 99 помилок.
Після аналізу PenfieldLabs виявили, що 100% результат MemPalace з’являється через встановлення кількості пошукових витягувань на 50 разів, але на тестових діалогах максимальна кількість рівнів становить лише 32. Це означає, що система напряму обходить етап витягування й передає всі дані AI-моделі для читання.
Щодо 100% результату LongMemEval команду виявили таку, що націлена на 3 конкретні проблеми, у яких було зосереджено помилки розробки, і написала спеціальний код для виправлення; існує підозра, що це зроблено для шахрайства на тестовому наборі.

Джерело зображення: Reddit Колеги PenfieldLabs вказали, що заявити про 100% на датасеті LoCoMo математично неможливо
Практична перевірка на GitHub: оціночні тести містять елементи введення в оману
Користувач GitHub hugooconnor після практичної перевірки прокоментував: MemPalace заявляє про точність пошуку до 96,6%, але фактично не використала жодного разу архітектуру «палацу пам’яті», яку рекламували. Hugooconnor каже, що їхній тест просто викликав стандартну функцію базового сховища ChromaDB і не мав нічого спільного з логікою класифікації крил, кімнат чи шухляд, на які робив акцент проєкт.
Після тестування hugooconnor виявив, що коли система справді вмикає власну логіку класифікації цих «палаців пам’яті», результат пошуку, навпаки, погіршується. Наприклад, у режимі «кімната» точність падає до 89,4%, а після ввімкнення технології стиснення AAAK точність ще нижча — 84,2%; у двох випадках обидва показники нижчі за продуктивність стандартної бази даних.
Hugooconnor також розкритикував методологію тестування: середовище тестування MemPalace спеціально звужує діапазон витягування для кожного питання до приблизно 50 етапів діалогу; шукати відповідь у надзвичайно малій тестовій базі надто просто.
Якщо розширити діапазон до більш реалістичних сценаріїв із понад 19 000 етапів діалогу, точність традиційного пошуку за ключовими словами падає до 30%, що демонструє: нинішній формат тестування MemPalace приховує справжню складність пошуку.
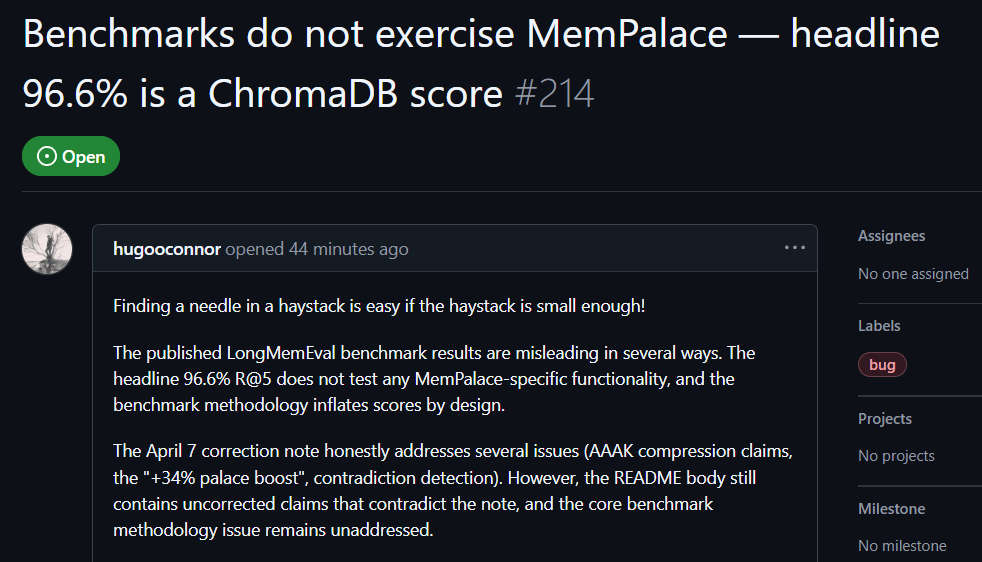
Джерело зображення: GitHub Практична перевірка користувачів GitHub: у базових тестах MemPalace є елементи введення в оману
Водночас, хоча розробницька команда вже опублікувала заяву про виправлення та визнала, що технологія AAAK справді є стисненням із втратою, і пообіцяла коригувати документи та дизайн системи відповідно до суворої критики спільноти, основний файл опису проєкту досі зберігає кілька невиправлених перебільшень, зокрема заяви про 30-кратне безповоротне стиснення та 34% підвищення точності пошуку; і порівняльні графіки з іншими конкурентами також повністю позбавлені джерел і походження.
Вихідний код MemPalace стикається з багатьма Bug
Зі збільшенням кількості розробників, які завантажують тести, на платформі GitHub з’явилась велика кількість повідомлень про баги у вихідному коді MemPalace.
Користувач cktang88 перелічив кілька серйозних недоліків: зокрема, інструкція для стиснення не працює й призводить до падіння системи, помилка в логіці підрахунку кількості слів у підсумку, неточні статистичні дані для «копання» кімнат, а також те, що сервер щоразу при виклику завантажує всю інтерпретовану інформацію в пам’ять, створюючи серйозні проблеми з витратами ресурсів.
Інші проблеми, на які також вказали, включають те, що система жорстко записує імена членів сім’ї розробника в стандартний конфіг-файл, а також існує примусове верхнє обмеження у 10k записів під час виведення стану запиту.
Для цих проблем відкрита спільнота вже почала активно виправляти. Користувач adv3nt3 подав кільказапитів навиправлення, зокрема виправлення статистичних даних для «копання», видалення стандартно заданих імен членів сім’ї та відтермінування часу ініціалізації знань із графа.** У подальшому розробницька команда також визнала ці помилки й через співпрацю з спільнотою поступово вирішує проблеми в коді.
Vibe Coding від Міли Йовович дуже круте, а от маркетинг — не дуже
Щодо цього проєкту MemPalace користувач Hacker News darkhanakh зробив такий висновок: MemPalace створює відчуття на кшталт OpenClaw — штучне маніпулювання результатами базового тесту (benchmark), аби зробити їх схожими на ідеально бездоганні, а потім упакувати це як якийсь значущий прорив для маркетингу.
Він вважає, що нижчорівнева технологія MemPalace можливо справді цікава, але за наявності таких недоліків у методі тестування, і ще й просувати це як «найвищий публічний результат в історії», це виглядає недоречно. «Але, щодо того, що Міла Йовович грає у Vibe Coding — я думаю, що це все ж доволі круто.»
Додаткове читання:
AI пише код і виходить косяк! Проблема з кібербезпекою в додатку «惜食獵人» про товари зі строком придатності з супермаркету, домашній GPS повністю оголює дані

