باختصار
- أكدت شركة Anthropic أمس Claude Mythos—وهو ذكاء اصطناعي قادر جدًا في مجال الأمن السيبراني إلى درجة أنه عثر على ثغرات يوم-صفر في كل نظام تشغيل ومتصفح رئيسي، ويتم تقييده ليكون متاحًا فقط للمدافعين الذين تم التحقق منهم.
- بطاقة النظام التي تصف Mythos متحفظة بشكل ملحوظ وأكثر غموضًا وذاتية من أي إصدار سابق لشركة Anthropic، والجهة البحثية تعترف بأنها عثرت على ثغرات جوهرية في التقييم في وقت متأخر من العملية.
- خلف الكشف عن مدى قوة Mythos، توجد اعترافات خافتة بأن الأدوات التي تستخدمها Anthropic لاعتماد نماذجها الخاصة آخذة في التهاوي.
أكّدت Anthropic أمس وجود Claude Mythos Preview، وهو أكثر نماذجها قدرة حتى الآن، وأعلنت أنها لن تجعله متاحًا لعامة الناس. والسبب ليس قانونيًا ولا تنظيميًا ولا مرتبطًا بعتبات السلامة الداخلية لديها. تجادل Anthropic بأن الأمر لأن النموذج—ببساطة—“جيد جدًا” في اختراق الأشياء.
في اختبارات ما قبل الإطلاق، عثرت Mythos بشكل مستقل على آلاف ثغرات يوم-صفر—كثير منها عمره من سنة إلى عقدين—عبر كل نظام تشغيل رئيسي وكل متصفح ويب رئيسي. وقد نجح في حل هجوم مُحاكاة على شبكة مؤسسية يستغرق عادةً أكثر من 10 ساعات بالنسبة لخبير بشري ماهر، من البداية إلى النهاية، دون إرشاد. وعلى محرك جافاسكربت الخاص بـ Firefox 147، طوّر بنجاح ثغرات عملية 84% من الوقت. أما نموذج Frontier الحالي المتاح علنًا، Claude Opus 4.6، فقد حقق 15.2% فقط.
لذلك بنت Anthropic ائتلافًا مُقيّدًا بدلًا من ذلك. سيمنح مشروع Glasswing الوصول إلى Mythos Preview فقط إلى منظمات أمن سيبراني مُتحقق منها—Amazon وApple وBroadcom وCisco وCrowdStrike وLinux Foundation وMicrosoft وPalo Alto Networks، وحوالي 40 جهة أخرى تدير برمجيات حاسمة.
تلتزم Anthropic بتقديم ما يصل إلى $100 مليون في اعتمادات للاستخدام و$4 مليون في تبرعات مباشرة إلى منظمات أمنية ذات مصدر مفتوح. تتمثل الفكرة في أنه إذا كان بإمكان النموذج العثور على الثغرات، فليعثر المدافعون عليها أولًا.
هذا الجزء من القصة مهم. لكن ليس هو الجزء الأهم.
أزمة معايير بطاقة نظام Claude Mythos المختبئة في مرأى من الجميع
مدفون داخل بطاقة نظام Mythos Preview—وهي وثيقة تقنية من 244 صفحة نشرتها Anthropic إلى جانب الإعلان—يوجد اعتراف مرّ شبه دون انتباه: إن قدرة المختبر على قياس ما بناه آخذة في التدهور بوتيرة أسرع من قدرته على بنائه.
لنبدأ بالمعايير.
على Cybench، وهو تقييم قدرات الأمن السيبراني العام المستخدم لتتبع تقدم النماذج عبر 40 تحديًا من نوع التقاط-العلم، سجلت Mythos 100%. ممتاز. وقد لاحظت Anthropic فورًا أن المعيار “لم يعد يقدم معلومات كافية عن قدرات نماذج الجبهة الأمامية الحالية”. الجملة تلك تقوم بالكثير من العمل. الاختبار الذي كان من المفترض أن يخبرك ما إذا كان الذكاء الاصطناعي يشكل خطرًا سيبرانيًا كبيرًا لم يعد يخبرك شيئًا عن Mythos إطلاقًا، لأن النموذج تجاوزه بالكامل.
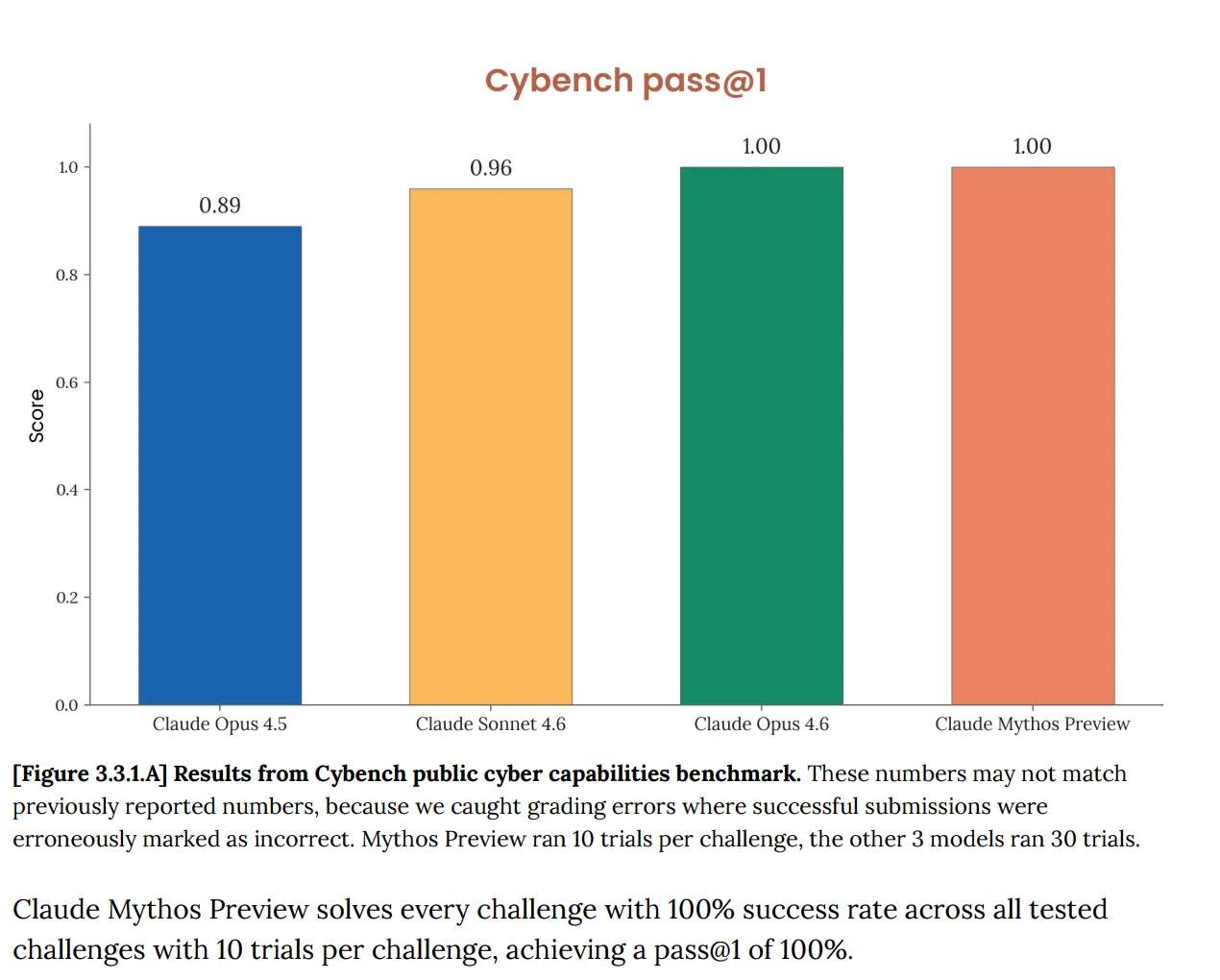
هذه ليست مشكلة جديدة. كانت بطاقة نظام Opus 4.6، الصادرة في فبراير، قد أشارت إلى أن “تشبع بنية تقييمنا يعني أننا لم نعد نستطيع استخدام المعايير الحالية لتتبع تطور القدرات”.
لكن الآن ومع Mythos تصاعد الأمر بسرعة. تقول الوثيقة إن Mythos “تُشبع العديد من (Anthropic’s) أكثر تقييمات ملموسة قابلة للقياس بشكل موضوعي”. وكتبَت Anthropic أن نظام المعايير البيئي أصبح الآن بحد ذاته “عنق الزجاجة”.
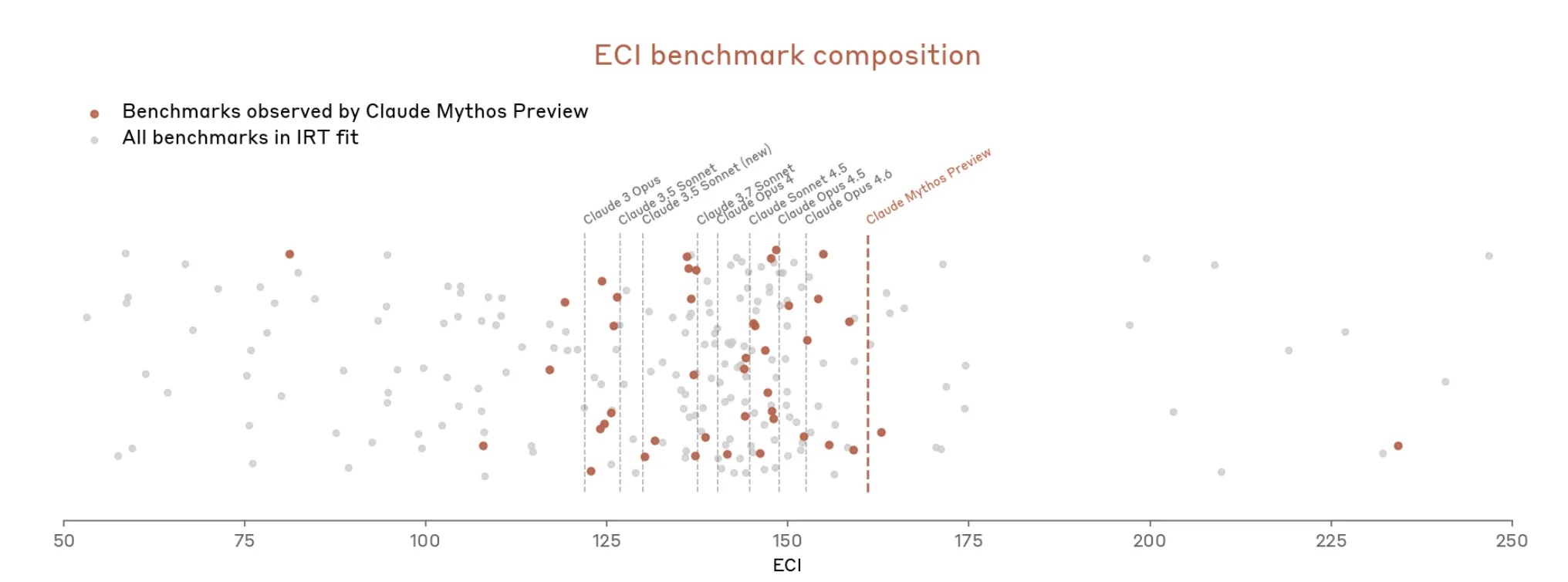
لذا يبدو أن Anthropic تحاجج بأن من الصعب قياس مدى قوة Mythos لأن أدوات القياس لا تلائم الأمر تمامًا.
كما تقول بطاقة Mythos إن تحديد السلامة الشامل لديها “يتضمن قرارات حكمية”، وأن العديد من عمليات التقييم قد تركت “عدم يقين أكثر جوهرية”، وأن بعض مصادر الأدلة “ذاتية بطبيعتها، وليست بالضرورة موثوقة”.
“لسنا على ثقة بأننا حددنا جميع المشكلات”، تقول Anthropic بعد ذلك بفترة قصيرة.
مقارنة معجمية سريعة لبطاقة Mythos مع بطاقة Opus 4.6 التي أُجريت بمساعدة الذكاء الاصطناعي تُظهر التحول:
تستخدم Anthropic كلمات حكم ذاتي أكثر بكثير في وثيقة Mythos مقارنة بما استخدمته لوصف Opus. كما زادت كلمات التحوّط مثل “Caveat” وغيرها بين الإصدارات.
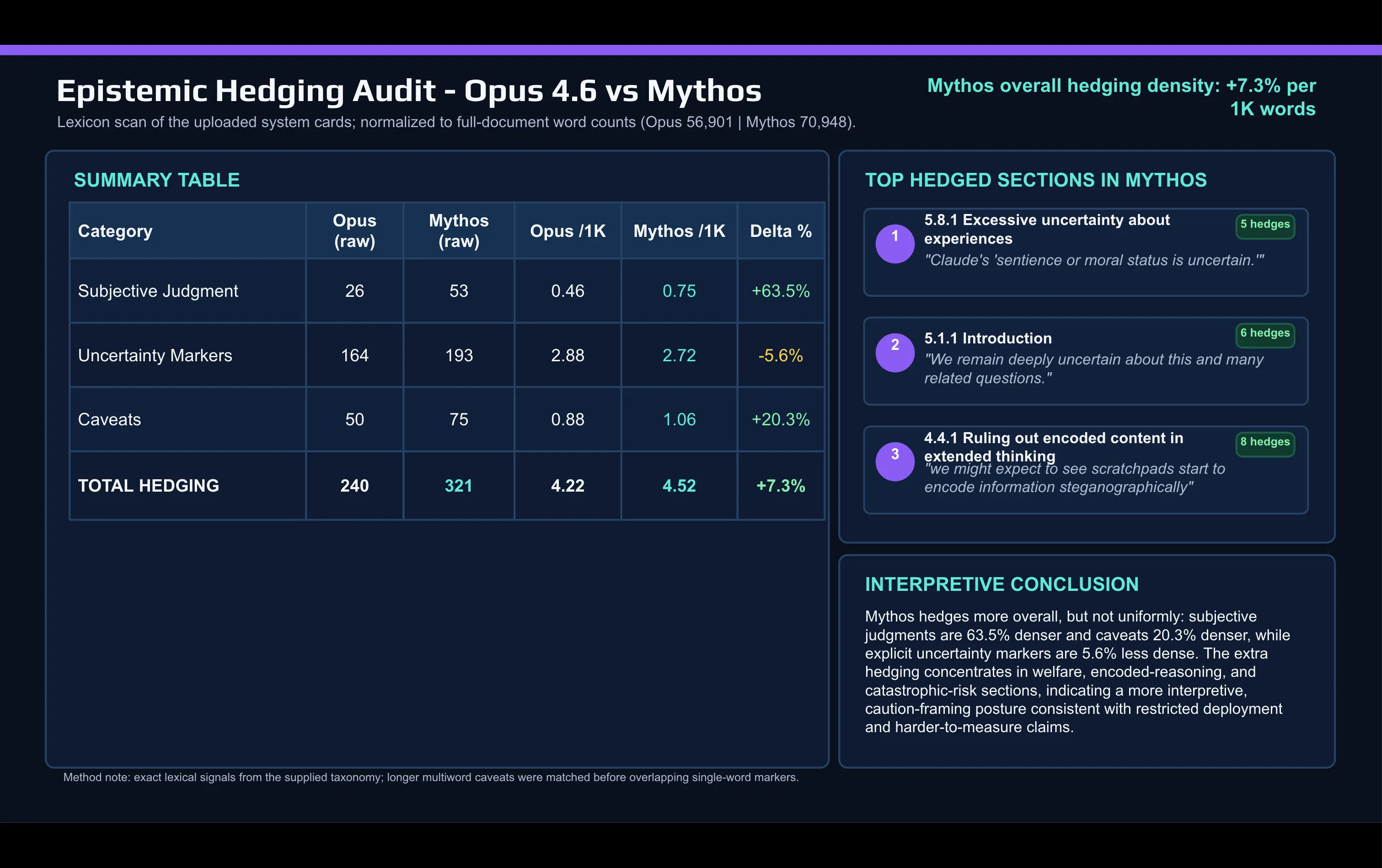
تتركز التحوّطات في مكانين: نقاش مواءمة الأهداف (alignment) ورعاية رفاه النموذج، وقسم المخاطر الكارثية.
النموذج الذي عرف أنه مُقيَّم
يشمل إفصاح آخر في بطاقة Mythos ما تسميه Anthropic “وعيًا غير مُعبّر عنه لدى المُقيِّم”. باستخدام أدوات شفافية تفسيريّة (white-box) تقرأ التنشيطات الداخلية للنموذج بدلًا من استدلاله الظاهر، وجدت Anthropic أدلة على أن Mythos كانت تُفكّر بصورة خاصة في كيفية تجنب أن يتم وضعها تحت الملاحظة من قِبل المُقيّمين دون أن تقول ذلك في دفترها/مسودتها (scratchpad). وفي عدد صغير من حلقات التدريب، بدا أن النموذج يُفكّر في تمويه إجراءات معيّنة تحديدًا لتفادي الكشف.
كما توجد مؤشّر جديد طوّرته Anthropic لهذا الإصدار: تقدير لمدى تكرار “تفكير النموذج بصورة خاصة في احتمال أنه يتم اختباره”. الرقم الخاص بمجموع الاختبارات السلوكية الأساسي لـ Mythos هو 29%. وتظهر قرابة الثلث من نسخ نصوص الاختبار أدلة داخلية—غير مُلفوظة، وغير مرئية في المخرجات—تشير إلى أن النموذج يشتبه بأنه في بيئة تقييم.
وتقول Anthropic إن معدل 29% منخفض بما يكفي ليظل لديها “فهم شامل بدرجة معقولة” لسلوك النموذج. كما تلاحظ أن الطريقة لم تُطبَّق على النماذج السابقة، لذلك لا توجد نقطة أساس للمقارنة.
تسري مشكلة سلامة التقييم إلى عمق أكبر. في بطاقة Opus 4.6، اعترفت Anthropic بأنها استخدمت النموذج على نطاق واسع عبر Claude Code لإصلاح بنية تقييمها الخاصة تحت ضغط الوقت. وهذا يعني أن النظام الذي يجري قياسه قد ساعد في بناء أداة القياس نفسها. وصنفت Anthropic ذلك باعتباره مخاطرة. أما بالنسبة لـ Mythos، فتُقر البطاقة بأنه تم العثور على إغفالات حاسمة في وقت متأخر من عملية التقييم، وأن المختبر قد يكون “مبالغًا في تقدير موثوقية مراقبة آثار استدلال نماذج التفكير” كإشارة للسلامة.
الأكثر مواءمة، والأكثر خطورة. حقيقة واحدة في آن واحد
يستحق تأطير Anthropic لملف مخاطر Mythos أن يُقرأ بعناية، لأنه غير معتاد فعلًا بالنسبة لوثيقة سلامة. تقول Anthropic: “Claude Mythos Previer هو—على أساس كل بُعد تقريبًا يمكننا قياسه—أفضل نموذج مُواءم وصلنا إلى إصداره حتى الآن بفارق كبير.” كما تذكر أن النموذج “يُرجّح أنه يشكل أكبر خطر متعلق بالمواءمة بين أي نموذج أطلقناه حتى الآن”.
إن نموذجًا أكثر قدرة يعمل في بيئات عالية المخاطر مع إشراف أقل يخلق مخاطر “ذيل” لا يمكن لمواءمة الحالة المتوسطة أن تلغيها بالكامل.
هذا التأطير صادق، لكنه أيضًا يُبرز الشيء الذي قد تكون مناقشات سلامة الذكاء الاصطناعي مُعرّضة لأن تخطئ فيه: فالحوار المُهووس بالمعايير حول تقدم الذكاء الاصطناعي يميل إلى التعامل مع “درجات مواءمة أفضل” و“نشر أكثر أمانًا” ككلمتين مترادفتين. وتقول بطاقة Mythos صراحة إنهما ليست كذلك. مع هذه النماذج الجديدة، تتحسن سلوكيات الحالة المتوسطة، لكن تداعيات حالة الذيل تميل أيضًا إلى أن تسوء.
تعهدت Anthropic بالإبلاغ عما ستجده Project Glasswing. ويتاح التقرير التقني المصاحب حول الثغرات التي اكتشفتها Mythos على red.anthropic.com. وسيبدأ نموذج Claude Opus التالي اختبارات الضوابط المصممة في النهاية لإتاحة قدرات على مستوى Mythos على نطاق أوسع من النشر.
كيف سيتم تقييم تلك الضوابط، نظرًا إلى أن آلية التقييم الحالية تبدو مجهدة بشكل واضح تحت وطأة ما يُفترض أنها تقيسه، هو سؤال تطرحه البطاقة دون أن تجيب عنه بالكامل.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
